
Low Power Split Radix FFT Processors Using Radix 2 Butterfly Units
Original price was: ₹16,000.00.₹10,000.00Current price is: ₹10,000.00.
Source : VHDL
Abstract:
Split radix fast Fourier Transform (SRFFT) is an ideal candidate for the implementation of a low power FFT processor, because it has the lowest number of arithmetic operation among all the FFT algorithms. In the design of such processors, an efficient addressing scheme for FFT data as well as twiddle factors is required. The signal flow graph of SRFFT is the same as radix-2 FFT, and therefore, the conventional address generation schemes of FFT data could also be applied to SRFFT. However SRFFT has irregular locations of twiddle factors and forbids the application of radix-2 address generation methods. This brief presents a shared memory low power SRFFT processor architecture. The SRFFT can be computed by using a modified radix-2 butterfly unit. The butterfly unit exploits the multiplier-gating technique to save dynamic power at the expense of using more hardware resources. In addition, two novel address generation algorithm for both the trivial and nontrivial twiddle factors are developed. In this paper We increases the architecture size, of radix-4 and 2048 point complex valued transform, and shown the performance of area, power and delay, and synthesized xilinx FPGA on s6lx16-2csg225.
List of the following materials will be included with the Downloaded Backup:
Related products
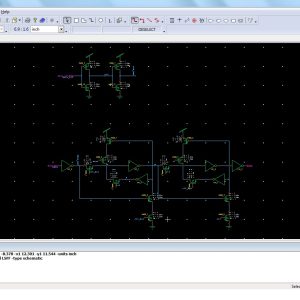
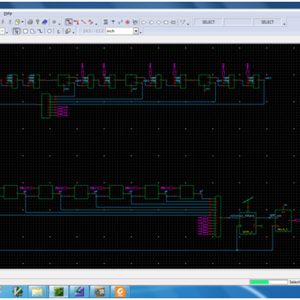


 Low Power Split Radix FFT Proc...
Low Power Split Radix FFT Proc...
Original price was: ₹16,000.00.₹10,000.00Current price is: ₹10,000.00.
Reviews
There are no reviews yet.