₹12,000.00Original price was: ₹12,000.00.₹8,000.00Current price is: ₹8,000.00.
Source : VHDLAbstract:
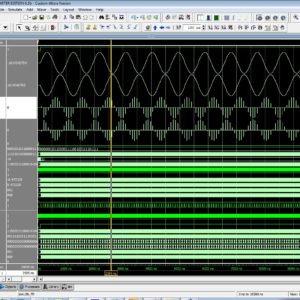
Fast Fourier transform (FFT) coprocessor, having a significant impact on the performance of communication systems, has been a hot topic of research for many years. The FFT function consists of consecutive multiply add operations over complex numbers, dubbed as butterfly units. Applying floating-point (FP) arithmetic to FFT architectures, specifically butterfly units, has become more popular recently. It offloads compute-intensive tasks from general-purpose processors by dismissing FP concerns (e.g., scaling and overflow/underflow). However, the major downside of FP butterfly is its slowness in comparison with its fixed-point counterpart. This reveals the incentive to develop a high-speed FP butterfly architecture to mitigate FP slowness. This brief proposes a fast FP butterfly unit using a devised FP fused-dot product-add (FDPA) unit, to compute AB±CD±E, based on binary signed-digit (BSD) representation. The FP three-operand BSD adder and the FP BSD constant multiplier are the constituents of the proposed FDPA unit. A carry-limited BSD adder is proposed and used in the three-operand adder and the parallel BSD multiplier so as to improve the speed of the FDPA unit. Moreover, modified Booth encoding is used to accelerate the BSD multiplier. The synthesis results show that the proposed FP butterfly architecture is much faster than previous counterparts but at the cost of more area. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
₹20,000.00Original price was: ₹20,000.00.₹12,000.00Current price is: ₹12,000.00.
Source : VHDLAbstract:
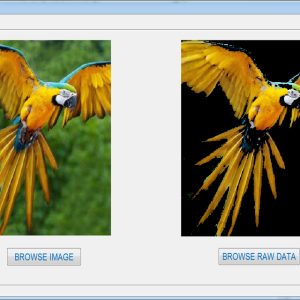
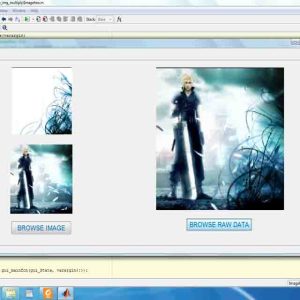
Graph cut has proven to be an effective scheme to solve a wide variety of segmentation problems in vision and graphics community. The main limitation of conventional graph-cut implementations is that they can hardly handle large images or videos because of high computational complexity. Even though there are some parallelization solutions, they commonly suffer from the problems of low parallelism (on CPU) or low convergence speed (on GPU). In this paper, we present a novel graph-cut algorithm that leverages a parallelized jump flooding technique and an heuristic push-relabel scheme to enhance the graph-cut process, namely, back-and-forth relabel, convergence detection, and block-wise push-relabel. The entire process is
parallelizable on GPU, and outperforms the existing GPU-based implementations in terms of global convergence, information propagation, and performance. We design an intuitive user interface for specifying interested regions in cases of occlusions when handling video sequences. Experiments on a variety of data sets, including images (up to 15 K×10 K), videos (up to 2.5K×1.5K×50), and volumetric data, achieve highquality results and a maximum 40-fold (139-fold) speedup over
conventional GPU (CPU-)-based approaches.
List of the following materials will be included with the Downloaded Backup:
₹15,000.00Original price was: ₹15,000.00.₹10,000.00Current price is: ₹10,000.00.
Source Code : VHDLAbstract:
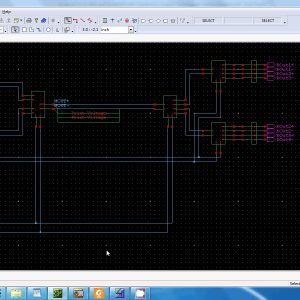
Inexact computing is particularly interesting for computer arithmetic designs. Implementation of 8X8 truncated multipliers using Very High Speed Integrated Circuit Hardware Description Language (VHDL). Truncated multipliers can be used in the image multiplication application. This multiplier is automatically truncating the output and reduces the power consumption and are comparing to other multipliers. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
₹10,000.00Original price was: ₹10,000.00.₹7,000.00Current price is: ₹7,000.00.
Source Code : TANNERAbstract:
This paper explores the use of transformer-coupled (TC) technique for the 2:1 MUX and the 1:2 DEMUX to serialize-and-deserialize (SerDes) high-speed data sequence. The widely used current-mode logic (CML) designs of latch and multiplexer/demultiplexer (MUX/DEMUX) are replaced by the proposed TC approach to allow the more headroom and to lower the power consumption. Through the stacked transformer, the input clock pulls down the differential source voltage of the TC latch and the TC multiplexer core while alternating between the two-phase operations. With the enhanced drain-source voltage, the TC design attracts more drain current with less width-to-length ratio of NMOS than that of the CML counterpart. The source-offset voltage is decreased so that the supply voltage can be reduced. The lower supply voltage improves the power consumption and facilitates the integration with low voltage supply SerDes interface. The MUX and the DEMUX chips are fabricated in 65-nm standard CMOS process and operate at 0.7-V supply voltage. The chips are measured up to 40-Gb/s with sub-hundred milliwatts power consumption.
List of the following materials will be included with the Downloaded Backup:
₹10,000.00Original price was: ₹10,000.00.₹6,000.00Current price is: ₹6,000.00.
Source Code : VHDL
Abstract:
The implementation of residue number system reverse converters based on well-known regular and modular parallel prefix adders is analyzed. The VLSI implementation results show a significant delay reduction and area × time2 improvements, all this at the cost of higher power consumption, which is the main reason preventing the use of parallel-prefix adders to achieve high-speed reverse converters in nowadays systems. Hence, to solve the high power consumption problem, novel specific hybrid parallel-prefix-based adder components those provide better tradeoff between delay and power consumption. The power, area and delay of the proposed system are analysis using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
We can provide Online Support Wordlwide, with proper execution, explanation and additionally provide explanation video file for execution and explanations.
24/7 Support Center
NXFEE, will Provide on 24x7 Online Support, You can call or text at +91 9789443203, or email us nxfee.innovation@gmail.com
Terms & Conditions:
Customer are advice to watch the project video file output, and before the payment to test the requirement, correction will be applicable.
After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
Online support will not be given more than 3 times.
On first time explanation we can provide completely with video file support, other 2 we can provide doubt clarifications only.
If any Issue on Software license / System Error we can support and rectify that within end of day.
Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
After payment, to must send the payment receipt to our email id.
Powered by NXFEE INNOVATION, Pondicherry.
Call us today at : +91 9789443203 or Email us at nxfee.innovation@gmail.com