₹18,000.00Original price was: ₹18,000.00.₹10,000.00Current price is: ₹10,000.00.
Source Code : VHDL & VERILOG HDL
Abstract:
This paper proposes efficient constant multiplier architecture based on vertical-horizontal binary common sub-expression elimination (VHBCSE) algorithm for designing a reconfigurable finite impulse response (FIR) filter whose coefficients can dynamically change in real time. To design an efficient reconfigurable FIR filter, according to the proposed VHBCSE algorithm, 2-bit binary common sub-expression elimination (BCSE) algorithm has been applied vertically across adjacent coefficients on the 2-D space of the coefficient matrix initially, followed by applying variable-bit BCSE algorithm horizontally within each coefficient. Faithfully rounded truncated multiple constant multiplication/accumulation (MCMAT) and multi-root binary partition graph (MBPG) respectively. Efficiency shown by the results of comparing the FPGA and ASIC implementations of the reconfigurable FIR filter designed using VHBCSE algorithm based constant multiplier establishes the suitability of the proposed algorithm for efficient fixed point reconfigurable FIR filter synthesis.
List of the following materials will be included with the Downloaded Backup:
₹25,000.00Original price was: ₹25,000.00.₹14,000.00Current price is: ₹14,000.00.
Source : VHDL
Abstract:
FIR (Finite Impulse Response) Filters: the finite impulse response filter is the most basic components in digital signal processing systems are widely used in communications, image processing, and pattern recognition. Based on FPGA(editable logic device) to achieve FIR filter, not only take into account the fixed -function DSP-specific chip real-time, but also has the DSP processor flexibility. The combination of FPGA and DSP technology can further improve integration, increase work speed and expand system capabilities.
List of the following materials will be included with the Downloaded Backup:
₹12,000.00Original price was: ₹12,000.00.₹6,000.00Current price is: ₹6,000.00.
Source : Verilog HDL
Proposed Abstract:
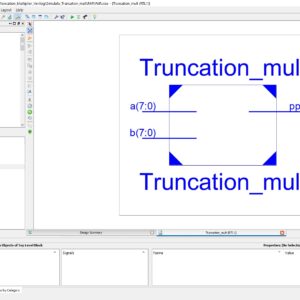
The operation of multiplication is an often encountered need in the field of digital signal processing. Parallel multipliers provide a rapid approach for performing multiplication operations, while demanding a significant amount of space in VLSI (Very Large Scale Integration) implementations. In the majority of signal processing applications, there is a preference for using a rounded result in order to prevent an increase in the size of the word. Therefore, an important goal in the design process is to minimize the spatial demand of the rounded output multiplier. This study introduces a novel approach to parallel multiplication that efficiently calculates the products of two n-bit values by selectively summing the most important columns using a variable correction technique. This research furthermore includes a comparative analysis of the implementation of 8X8 conventional and truncated multipliers using Verilog Hardware Description Language (HDL) on Field Programmable Gate Arrays (FPGAs). The shortened multiplier demonstrates a much greater decrease in device consumption as compared to the regular multiplier. A conventional multiplier performs computations on n x n bits and produces a weighted sum of the output, consisting of 2n bits. In contrast, a truncated multiplier generates an output of just n bits from the n x n bit input. The use of logic gates in both internal and external hardware design will be decreased. Truncated multipliers provide a viable approach for achieving significant reductions in FPGA resources, latency, and power consumption compared to regular parallel multipliers, particularly in scenarios where the complete accuracy provided by the standard multiplier is unnecessary.
List of the following materials will be included with the Downloaded Backup:
₹16,000.00Original price was: ₹16,000.00.₹8,000.00Current price is: ₹8,000.00.
Source : Verilog HDL
"Cost Only for Source Code, not FPGA Hardware"
Proposed Abstract:
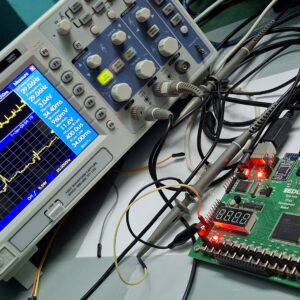
This project presents the design and implementation of an ECG-DAC-SPI interface for medical applications using the Xilinx Spartan-6 FPGA platform and the MCP4921 12-bit SPI DAC. The objective is to process pre-recorded ECG signals from the MIT-BIH database, reconstruct the signal digitally, and output it as an accurate analog waveform suitable for real-time monitoring and simulation. The system is designed to meet the stringent requirements of medical-grade signal fidelity and low-latency processing. The FPGA-based implementation comprises several key modules, including digital ECG data acquisition, optional noise filtering, and a custom SPI communication controller. The ECG signal, preloaded into FPGA memory, is scaled and quantized to match the 12-bit resolution of the MCP4921 DAC. A low-pass FIR filter is implemented on the FPGA to enhance signal quality by removing high-frequency noise, ensuring smooth signal. A Verilog HDL-based SPI controller facilitates precise communication with the DAC, synchronizing data transfer and ensuring real-time signal conversion. The reconstructed analog ECG waveform is visualized on an oscilloscope to validate its fidelity to the original dataset. The DAC, interfaced via the FPGA’s SPI controller, is chosen for its high resolution and compatibility with low-latency applications. The design is synthesized, implemented, and tested on the Xilinx Spartan-6 FPGA platform. The project includes extensive simulation and hardware testing, evaluating parameters such as SPI throughput, waveform accuracy, and system latency. Results demonstrate that the system achieves precise signal reconstruction and reliable analog output, suitable for medical applications. This work highlights the use of FPGA technology and the MCP4921 DAC for scalable and reconfigurable ECG signal processing systems. It provides a robust platform for integration into advanced medical devices, including real-time ECG monitors, simulators, and portable diagnostic tools. Future extensions of the design could include integration of live ECG sensors, advanced noise filtering, or wireless transmission for telemedicine applications.
List of the following materials will be included with the Downloaded Backup:
₹25,000.00Original price was: ₹25,000.00.₹15,000.00Current price is: ₹15,000.00.
Source : Verilog HDL
Base Paper Abstract:
A digital finite impulse response (FIR) filter is a ubiquitous block in digital signal processing applications and its behavior is determined by its coefficients. To protect filter coefficients from an adversary, efficient obfuscation techniques have been proposed, either by hiding them behind decoys or replacing them by key bits. In this article, we initially introduce a query attack that can discover the secret key of such obfuscated FIR filters, which could not be broken by the existing prominent attacks. Then, we propose a first of its kind hybrid technique, including both hardware obfuscation and logic locking using a point function for the protection of parallel direct and transposed forms of digital FIR filters. Experimental results show that the hybrid protection technique can lead to FIR filters with higher security while maintaining the hardware complexity competitive or superior to those locked by prominent logic locking methods. It is also shown that the protected multiplier blocks and FIR filters are resilient to existing attacks. The results on different forms and realizations of FIR filters show that the parallel direct form FIR filter has a promising potential for a secure design.
List of the following materials will be included with the Downloaded Backup:
₹25,000.00Original price was: ₹25,000.00.₹10,000.00Current price is: ₹10,000.00.
Source : TANNER EDA
Abstract:
The logic size, propagation delay, power of applications, based upon this improvement the adder design logic size will reduced year by year, here a proposed In recent technology of any application, adders is a more priority to do a function and task of arithmetic operation, in crucial this adder based arithmetic operation will decide work of this paper will design using a single bit full adder to design a multiplier. In this multiplier design, adder is a main priority to reduce the arithmetic logic size and increases speed of multiplier, in recent we have lots of multiplier design, Vedic multiplier, Wallace tree multiplier, booth multiplier, approximate multiplier. Here, the proposed work will taken truncated multiplier design, it's because, the truncated multiplier will have a capability to reduced internal and external architecture size in every design, regarding this truncated multiplier will have three options such as rounding, deleting, truncating, here the MSB bits will be truncated and present the output of n x n multiplication will provided only n bit level, using this truncated multiplier the proposed work will designed a 8-Tap FIR(Finite impulse response) filter and shown the efficiency of filter design using this CMOS GDI (Gate Diffusion Input) adder design. This proposed work will design in CMOS Logic gate and which 10-T transistor level of full adders with 90um technology, finally proved the terms of area, delay and power.
List of the following materials will be included with the Downloaded Backup:
₹16,000.00Original price was: ₹16,000.00.₹10,000.00Current price is: ₹10,000.00.
Source Code : VHDL
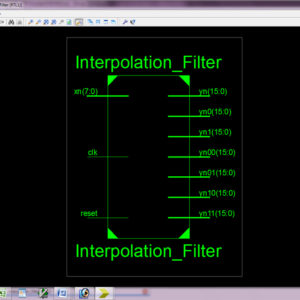
Abstract:
The input-matrix and the coefficient-matrix resizes when changes. An analysis of interpolation filter computation for different up-sampling factors is made in this paper to identify redundant computations and removed those by reusing partial results. Reuse of partial results eliminates the necessity of matrix resizing in interpolation filter computation. A novel block-formulation is presented to share the partial results for parallel computation of filter outputs of different up-sampling factors. Using the proposed block formulation, to increase the number of tab to 16 and to get the accuracy and reduce the delay. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
₹16,000.00Original price was: ₹16,000.00.₹10,000.00Current price is: ₹10,000.00.
Source Code : VHDL
Abstract:
Multirate technique is necessary for systems with different input and output sampling rates. Recent advances in mobile computing and communication applications demand low power and high speed VLSI DSP systems. In this paper to discuss the downsampling technique and its improvement, major drawbacks of present approaches possible to increase degeneracy. This Multirate design methodology is systematic and applicable to many problems. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
₹16,000.00Original price was: ₹16,000.00.₹10,000.00Current price is: ₹10,000.00.
Source : Verilog HDL
Base Paper Abstract:
Multiple Constant Multiplication (MCM) over integers is a frequent operation arising in embedded systems that require highly optimized hardware. An efficient way is to replace costly generic multiplication by bit-shifts and additions, i. e. a multiplier less circuit. In this work, we improve the state of-the-art optimal approach for MCM, based on Integer Linear Programming (ILP). We introduce a new low-level hardware cost metric, which counts the number of one-bit adders and demonstrate that it is strongly correlated with the LUT count. This new model permitted us to consider intermediate truncations that permit to significantly save resources when a full output precision is not required. We incorporate the error propagation rules into our ILP model to guarantee a user-given error bound on the MCM results. The proposed ILP models for multiple flavors of MCM are implemented as an open-source tool and, combined with an automatic code generator, provide a complete coefficient-to-VHDL flow. We evaluate our models in extensive experiments, and propose an in-depth analysis of the impact that design metrics have on synthesized hardware.
List of the following materials will be included with the Downloaded Backup:
2. Existing and Proposed Project Comparison with output video
3. Basic Documentation (20 to 30 Pages):
3.1 Proposed Title
3.2 Proposed Abstract
3.3 Advantages & Disadvantages
3.4 Improvement of this Project
3.5 Existing System with Notes
3.6 Proposed System with Notes
3.7 Literature Survey
3.8 Software Related Notes
3.9 VLSI and HDL Language / Tanner Notes
3.10 References & Reference Paper for More Pages
4. Online Support ( Any Desk / Zoom / Google Meet)
Provide Wordlwide Online Support
We can provide Online Support Wordlwide, with proper execution, explanation and additionally provide explanation video file for execution and explanations.
24/7 Support Center
NXFEE, will Provide on 24x7 Online Support, You can call or text at +91 9789443203, or email us nxfee.innovation@gmail.com
Terms & Conditions:
Customer are advice to watch the project video file output, and before the payment to test the requirement, correction will be applicable.
After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
Online support will not be given more than 3 times.
On first time explanation we can provide completely with video file support, other 2 we can provide doubt clarifications only.
If any Issue on Software license / System Error we can support and rectify that within end of day.
Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
After payment, to must send the payment receipt to our email id.
Powered by NXFEE INNOVATION, Pondicherry.
Call us today at : +91 9789443203 or Email us at nxfee.innovation@gmail.com