Proposed Title :
A Upgrades method of Floating-Point Fused Dot-Product Unit with using Sticky
Proposed System:
-
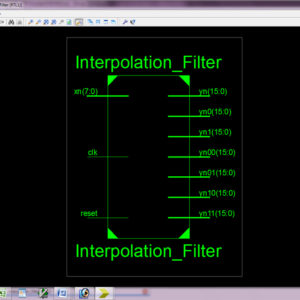
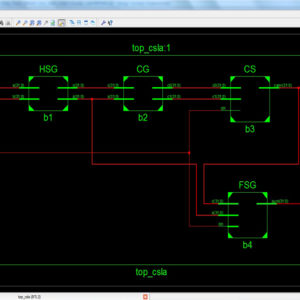
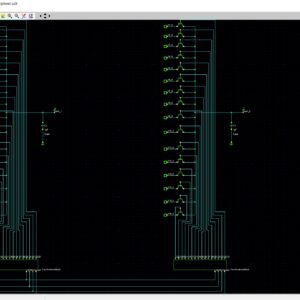
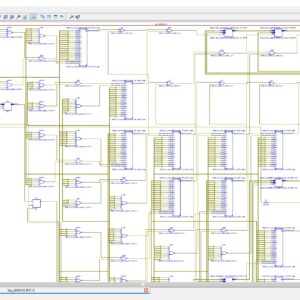
- To implement the Floating Point Fused Dot-Product Unit with using Sticky in C&D, and upgrade architecture.
Software implementation:
- VHDL

₹15,000.00 Original price was: ₹15,000.00.₹10,000.00Current price is: ₹10,000.00.
Source : VHDL
Abstract:
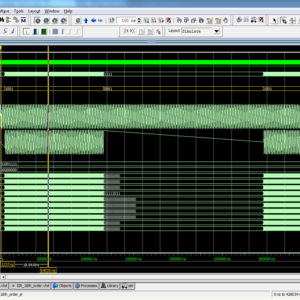
A floating-point fused dot-product unit is presented that performs single-precision floating-point multiplication and addition operations on two pairs of data in a time that is only 150% the time required for a conventional floating-point multiplication. When placed and routed in a 45nm process, the fused dot-product unit occupied about 70% of the area needed to implement a parallel dot-product unit using conventional floating-point adders and multipliers. The speed of the fused dot-product is 27% faster than the speed of the conventional parallel approach. The numerical result of the fused unit is more accurate because one rounding operation is needed versus at least three for other approaches.
List of the following materials will be included with the Downloaded Backup:
Proposed Title :
Proposed System:
Software implementation:
₹12,000.00 Original price was: ₹12,000.00.₹6,000.00Current price is: ₹6,000.00.


₹15,000.00 Original price was: ₹15,000.00.₹6,000.00Current price is: ₹6,000.00.
Copyright © 2024 Nxfee Innovation.
A Floating-Point Fused Dot-Pro...
₹15,000.00 Original price was: ₹15,000.00.₹10,000.00Current price is: ₹10,000.00.
Reviews
There are no reviews yet.