Proposed Title :
Reduction of Data Leakage Trojans in modulation scheme of TDMA with using DES Encoding and Decoding.
Improvement of this Project:
In this paper they are designed Time division multiplexing with using two technique of RECORD and COTS, in application of DES Algorithm.
Here we are proposed with same DES Algorithm with Encryption and Decryption method with BER Testing.
Software implementation:
- Modelsim & Xilinx
Proposed System:
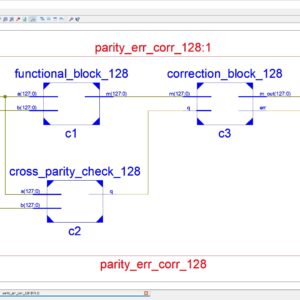
This paper explains the concept of reduction of data leakage Trajons in modulation scheme of TDM (Time Division Multiplexing) using DES (Data Encryption Standard) encoding and decoding concept. The DES is a symmetric key block cipher which is used for encryption and decryption process. In hardware manufacturing, detection and prevention of hardware Trajons attacks becomes a major concern for a manufacturing company. Because, the hardware Trajons is able to steal some sensitive information of a users such as encryption keys, passwords, etc,. So, most defensive methods prefers on prevention of data. The existing system uses the concept of RECORD ( Randomized encoding of combinational logic for resistance to data leakage) to prevent the data from the hardware Trajons even the Trajons known the entire information. Thus the proposed system of TDM version of RECORD design is more secure than the Sequential RECORD system and these case of existing work, will not concentrate and proved TDM RECORD DES Decryption Algorithm. Therefore, the proposed work of this paper will used the concept of TDM version of RECORD with implement in Encryption and Decryption Algorithm with BER Testing, this method will have designed in Verilog HDL and implement in Xilinx FPGA and finally shown the comparison results in terms of area, delay and power.
” Thanks for Visit this project Pages – Buy It Soon “
Combating Data Leakage Trojans in Commercial and ASIC Applications With Time-Division Multiplexing and Random Encoding
“Buy VLSI Projects On On-Line”
Terms & Conditions:
- Customer are advice to watch the project video file output, before the payment to test the requirement, correction will be applicable.
- After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
- After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
- Online support will not be given more than 3 times.
- On first time explanations we can provide completely with video file support, other 2 we can provide doubt clarifications only.
- If any Issue on Software license / System Error we can support and rectify that within end of the day.
- Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
- After payment, to must send the payment receipt to our email id.
- Powered by NXFEE INNOVATION, Pondicherry.
Payment Method :
- Pay Add to Cart Method on this Page
- Deposit Cash/Cheque on our a/c.
- Pay Google Pay/Phone Pay : +91 9789443203
- Send Cheque through courier
- Visit our office directly
- Pay using Paypal : Click here to get NXFEE-PayPal link