Proposed System:
- Reduced the Power consumption.
- Reduce the area size
Software Implementation:
- DSCH3
- MICROWIND
Hardware Implementation:
- ASIC

₹10,000.00 Original price was: ₹10,000.00.₹8,000.00Current price is: ₹8,000.00.
Source : DSCH3/MICROWIND
Abstract:
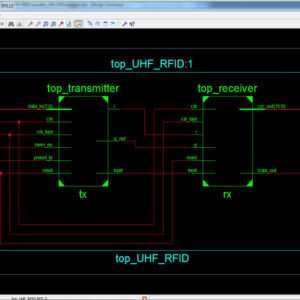
In this paper, we are proposed a level converting retention flip-flop for Zigbee Soc, it will be using to allows the voltage regulator that generates the core supply voltage (VDD, core), to be turned off in the standby mode, and it thus reduces the standby power of the Zigbee Soc. Here the Level up conversion form VDD core is achieved by and embedded nMOS pass transistor level-conversion scheme that uses a low only signal transmitting technique. By embedding a retention latch and level-up converter into the data-to-output path of the proposed RFF, the RFF resolves the problems of the static RAM-based RFF, such as large dc current and low readability caused by threshold drop. The proposed RFF does not also require additional control signals for power mode transitioning. Using 0.13-μm process technology, we implemented an RFF with VDD,core and VDD,IO of 1.2 and 2.5 V, respectively. The maximum operating frequency is 300 MHz. The active energy of the RFF is 191.70 fJ, and its standby power is 350.25 pW.
List of the following materials will be included with the Downloaded Backup:
Proposed System:
Software Implementation:
Hardware Implementation:
₹15,000.00 Original price was: ₹15,000.00.₹10,000.00Current price is: ₹10,000.00.


₹20,000.00 Original price was: ₹20,000.00.₹10,000.00Current price is: ₹10,000.00.
Copyright © 2026 Nxfee Innovation.
Level-Converting Retention Fli...
₹10,000.00 Original price was: ₹10,000.00.₹8,000.00Current price is: ₹8,000.00.
Reviews
There are no reviews yet.