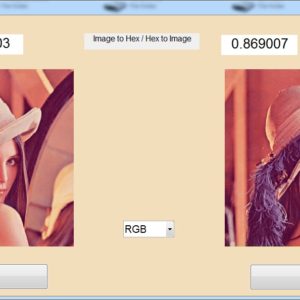
Proposed Title :
FPGA Implementation of Low-Power Y Cb and Cr based Approximate Multiplication With Configurable Error Recovery
Improvement of this Project:
To developed Image Multiplication with technique of both luminance and chrominance (Y Cb Cr).
To developed AM1 and AM2 Multiplication and compared all the terms of area, delay and power.
Software implementation:
- Modelsim
- Xilinx
Disadvantages:
- Longer delay
- High power consumption
- Low accuracy
- Only luminance multiplication is achieved ( Gray Scale )
Proposed System:
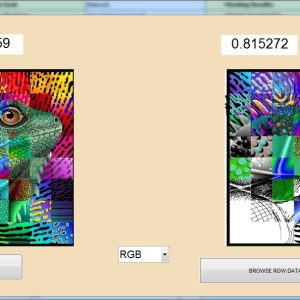
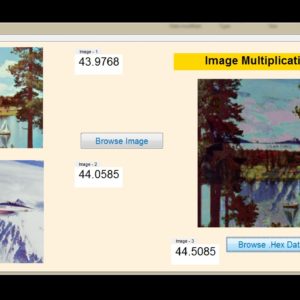
In Digital Signal Processing (DSP), which performance enhanced with low accuracy in application of approximate circuits. In existing system, which AM1 and AM2 are described for error recovery, which error has taken from approximate adder and then multiplexing with Approximate results. approximate multiplier with low power and small critical path is delivered with high performance DSP applications. An approximate adder is developed in existing technology of approximate Multipliers designed only in Luminance (Y) concept and achieved with image sharpening and smoothing. In proposed system, here present AM1 Multiplication and AM2 Multiplication and implemented both of the things in Image processing as multiplication with Y ( Luminance) and Chrominance (Cb, Cr) technique. These proposed system is coded by VHDL with luminance to luminance multiplication and chrominance to chrominance multiplication in this sampling is efficiently multiplied and proved in comparisons. A result of PSNR and SSIM is achieved by AM1 and AM2 Image Multiplication and this design proved synthesized in Xilinx FPGA XC5VLX330-2FF1760 and proved comparison in terms of power, area and delay.
” Thanks for Visit this project Pages – Buy It Soon “
Low-Power Approximate Unsigned Multipliers with Configurable Error Recovery
“Buy VLSI Projects On On-Line”
Terms & Conditions:
- Customer are advice to watch the project video file output, before the payment to test the requirement, correction will be applicable.
- After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
- After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
- Online support will not be given more than 3 times.
- On first time explanations we can provide completely with video file support, other 2 we can provide doubt clarifications only.
- If any Issue on Software license / System Error we can support and rectify that within end of the day.
- Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
- After payment, to must send the payment receipt to our email id.
- Powered by NXFEE INNOVATION, Pondicherry.
Payment Method :
- Pay Add to Cart Method on this Page
- Deposit Cash/Cheque on our a/c.
- Pay Google Pay/Phone Pay : +91 9789443203
- Send Cheque through courier
- Visit our office directly
- Pay using Paypal : Click here to get NXFEE-PayPal link