Proposed Title :
A Real-Time FHD Learning Based Super Resolution System Without a Frame Buffer
Improvement of this Project:
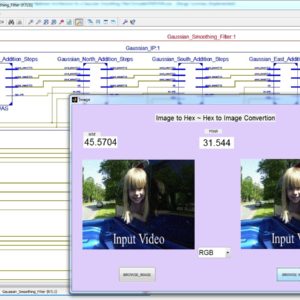
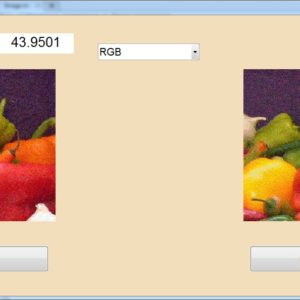
Increases the resolution 800×800 images to 1600×1600 image size with Vertical and Horizontal Interpolation technique using Bi-cubic method and find out SSIM and PSNR.
Configure Patch Feature Extraction and Dictionary Correlation with Kernel Coefficient method.
Software implementation:
- Modelsim
- Xilinx 14.2
Proposed System:
The main aim of the Single image (SR) super-resolution is to generate (HR) high-resolution images from (LR) low-resolution images. This paper briefly presents a concept of real time super resolution method of FHD based image extended and scaling processor. The super resolution system includes three blocks of operations. The first is a low-frequency interpolation stage, where bicubic interpolation is used for reconstructing the low-frequency parts of HR images. The second stage generates high-frequency patches by choosing the highest related pre-trained regression function according to each HR low frequency patch. In the third stage, with the high-frequency information, the low-frequency image patches are enhanced and overlapped to construct the SR result. These operations for gaining a high-frequency result are applied to the Y-luminance channel only, while the high-resolution Cb and Cr channels are generated by bicubic interpolation. The proposed system generates the output image resolution of 1920 X 1080 (FHD) by the input of 800 X 800 image size. The proposed architecture performs an anchored neighborhood regression algorithm that generates a high-resolution image from a low-resolution image input using only numbers of line buffers. Finally, super resolution technique is implemented in VHDL and Synthesized in the XILINX VERTEX-5 FPGA and shown the comparison for power, area and delay reports.
” Thanks for Visit this project Pages – Buy It Soon “
A Real-Time FHD Learning Based Super Resolution System Without a Frame Buffer
“Buy VLSI Projects On On-Line”
Terms & Conditions:
- Customer are advice to watch the project video file output, before the payment to test the requirement, correction will be applicable.
- After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
- After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
- Online support will not be given more than 3 times.
- On first time explanations we can provide completely with video file support, other 2 we can provide doubt clarifications only.
- If any Issue on Software license / System Error we can support and rectify that within end of the day.
- Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
- After payment, to must send the payment receipt to our email id.
- Powered by NXFEE INNOVATION, Pondicherry.
Payment Method :
- Pay Add to Cart Method on this Page
- Deposit Cash/Cheque on our a/c.
- Pay Google Pay/Phone Pay : +91 9789443203
- Send Cheque through courier
- Visit our office directly
- Pay using Paypal : Click here to get NXFEE-PayPal link