Proposed System:
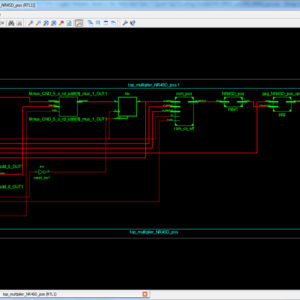
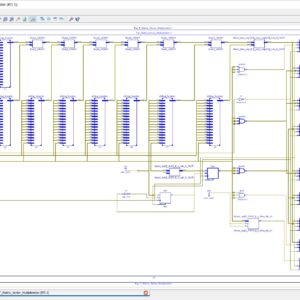
- MODIFIED WALLACE TREE MULTIP LIER USING RCA AND SQRT CSLA
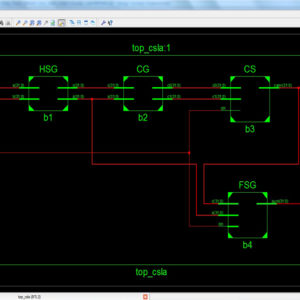
- SQRT CSLA USING COMMON BOOLEAN LOGIC
Advantages:
- Delay is reduced
- Area is reduced
- Power is reduced
Software Implementation:
- Modelsim 6.0
- Xilinx 14.2

₹12,000.00 Original price was: ₹12,000.00.₹8,000.00Current price is: ₹8,000.00.
Source Code : VHDL
Abstract:
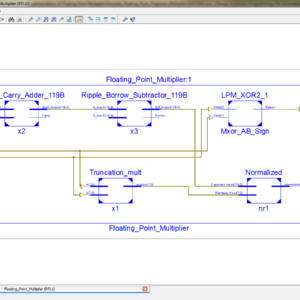
A multiplier is one of the key hardware blocks in most digital and high performance systems such as FIR filters, micro processors and digital signal processors etc. A system’s performance is generally determined by the performance of the multiplier because the multiplier is generally the slowest element in the whole system and also it is occupying more area consuming. The Carry Select Adder (CSLA) provides a good
compromise between cost and performance in carry propagation adder design. A Square Root Carry Select Adder using RCA is introduced but it offers some speed penalty. However, conventional CSLA is still area-consuming due to the dual ripple carry adder structure. In the proposed work, generally in Wallace multiplier the partial products are reduced as soon as possible and the final carry propagation path carry select adder is used. In this paper, modification is done at gate level to reduce area and power consumption. The Modified Square Root Carry Select-Adder (MCSLA) is designed using Common Boolean Logic and then compared with regular CSLA respective architectures, and this MCSLA is implemented in Wallace Tree Multiplier. This work gives the reduced area compared to normal Wallace tree multiplier. Finally an area efficient Wallace tree multiplier is designed using common Boolean logic based square root carry select adder.
List of the following materials will be included with the Downloaded Backup:
Proposed System:
Advantages:
Software Implementation:
₹15,000.00 Original price was: ₹15,000.00.₹6,000.00Current price is: ₹6,000.00.

 2")
₹16,000.00 Original price was: ₹16,000.00.₹10,000.00Current price is: ₹10,000.00.
Copyright © 2026 Nxfee Innovation.
Modified Wallace Tree Multipli...
₹12,000.00 Original price was: ₹12,000.00.₹8,000.00Current price is: ₹8,000.00.
Reviews
There are no reviews yet.