
Proposed Title :
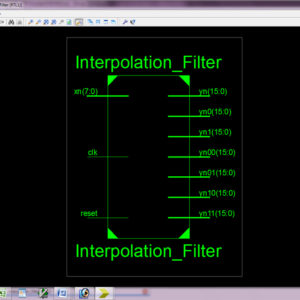
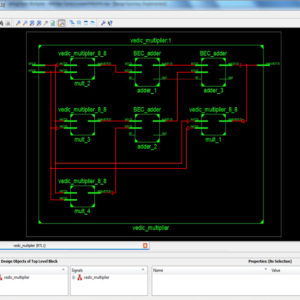
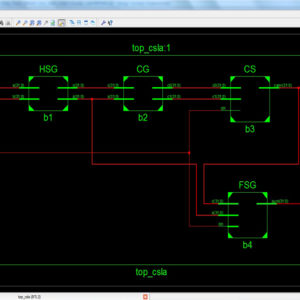
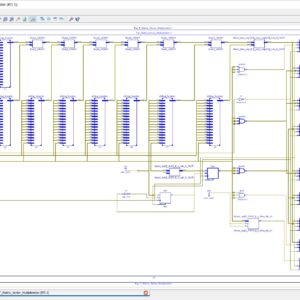
FPGA Implementation of Pre Encoded Non Redundant Radix 4 Signed Digit Encoding using Carry skip adder
Proposed System:
- In proposed system Non Redundant Radix 4 Signed Digit Encoding, to reduce the delay of the architecture design compared to existing system and increases the BIT size.
Software implementation:
- Model sim
- Xilinx 14.2


Reviews
There are no reviews yet.