Proposed Title :
FPGA Implementation of High Complexity method of Multiple Cell upsets in (15,7) BCH Codes in Space Applications.
Improvement of this Project:
To design Error Correction Codes for Multiple Cell Upsets in a method of BCH (15,7) Code with Syndrome Calculation of Multiple Error Correction and also compared with existing Hamming Code.
Software implementation:
- Modelsim & Xilinx
Proposed System:
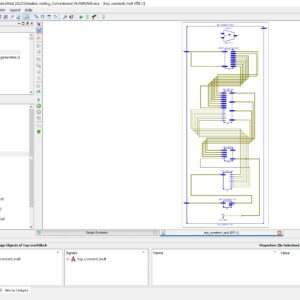
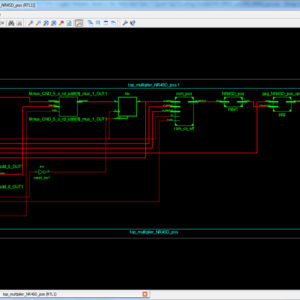
In a recent technology of Digital Signal Processing based application method will have number of errors will occur with integrated SRAM memory on during signal transmission and reception it will reliable with conventional fault tolerance technique with probability of occurrence in single-cell upsets and multiple cell upsets. In a existing thing will have a Hamming code will also present parity checks in bi-dimensional layout method to correct and detect the errors. The main drawback of the Hamming code can detect only one bit in error can be corrected and also detect some double error patterns, in addition to the SEC. In this paper presents this method on BCH Codes with Multiple Cell upsets, in this BCH Code can capable to detect and correct a Multiple Fault Error Corrections, and it will use variant check matrices to extend ideas from Hamming and Reed-Solomon Codes, with detect many errors. In this method to implement in VHDL and synthesized in Xilinx FPGA-S6LX9, finally compared with Hamming and BCH codes based Multiple-Cell Upsets of error correction and shown in the terms of area, delay and power.
” Thanks for Visit this project Pages – Buy It Soon “
Improving Error Correction Codes for Multiple-Cell Upsets in Space Applications
“Buy VLSI Projects On On-Line”
Terms & Conditions:
- Customer are advice to watch the project video file output, before the payment to test the requirement, correction will be applicable.
- After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
- After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
- Online support will not be given more than 3 times.
- On first time explanations we can provide completely with video file support, other 2 we can provide doubt clarifications only.
- If any Issue on Software license / System Error we can support and rectify that within end of the day.
- Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
- After payment, to must send the payment receipt to our email id.
- Powered by NXFEE INNOVATION, Pondicherry.
Payment Method :
- Pay Add to Cart Method on this Page
- Deposit Cash/Cheque on our a/c.
- Pay Google Pay/Phone Pay : +91 9789443203
- Send Cheque through courier
- Visit our office directly
- Pay using Paypal : Click here to get NXFEE-PayPal link