Proposed Title :
FPGA Implementation of SVM based Seizure Detection System with using Truncation Multiplier
Improvement of this Project:
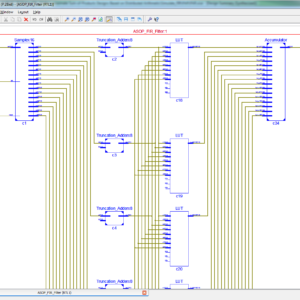
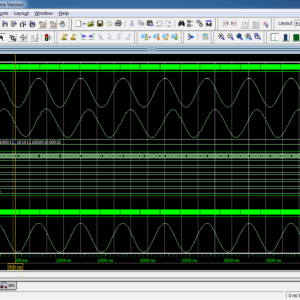
To develop SVM based Seizure Detection System with using Truncation Multiplier, and hence proved the Area, Power and Delay with using Synthesized in Xilinx XC6SLX100T-2CSG484 FPGA.
Software implementation:
- Modelsim
- Xilinx 14.2
Proposed System:
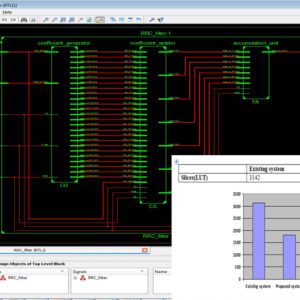
In this recent research of automatic seizure detection system is very convenient to monitor epilepsy patients in anywhere at the time of predictions previously and alert hospitals and related persons. In this work where design a high efficiency and attain high detection accuracy system of seizure detection in system on chip, this paper present with non linear support vector machine (SVM) with classifications method and also consists of seizure prediction feature extraction method. In the feature extraction method discrete wavelet transform will level Daubechies to fit the physiological bands of electroencephalogram (EEG) signals. In this existing system of SVM with modified sequential minimal optimization in Gaussian Kernel algorithm to perform efficient on chip learning, but it will take more logic size due to cause of more number of multipliers. Here, this proposed work presents this SVM with Gaussian Kernel algorithm design in Truncated method using Signed-Unsigned Truncation multiplier, it will reduced the area size in internal and external, thus its having n size outputs from n x n inputs, this experimental results will shown in VLSI System of XILINX FPGA XC6SLX100T-2CSG484, with proved in the terms of Area, delay and power.
” Thanks for Visit this project Pages – Buy It Soon “
VLSI Design of SVM-Based Seizure Detection System With On-Chip Learning Capability
“Buy VLSI Projects On On-Line”
Terms & Conditions:
- Customer are advice to watch the project video file output, before the payment to test the requirement, correction will be applicable.
- After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
- After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
- Online support will not be given more than 3 times.
- On first time explanations we can provide completely with video file support, other 2 we can provide doubt clarifications only.
- If any Issue on Software license / System Error we can support and rectify that within end of the day.
- Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
- After payment, to must send the payment receipt to our email id.
- Powered by NXFEE INNOVATION, Pondicherry.
Payment Method :
- Pay Add to Cart Method on this Page
- Deposit Cash/Cheque on our a/c.
- Pay Google Pay/Phone Pay : +91 9789443203
- Send Cheque through courier
- Visit our office directly
- Pay using Paypal : Click here to get NXFEE-PayPal link