IEEE Transactions on VLSI 2023
Following Novelty based Research Projects not yet Published in Any Journal
Customization Available for Journal Publications
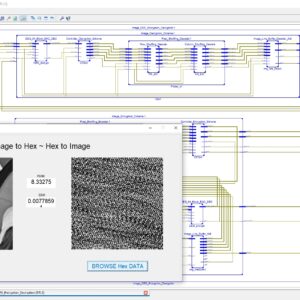
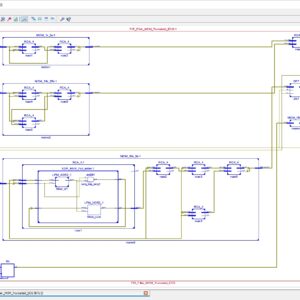
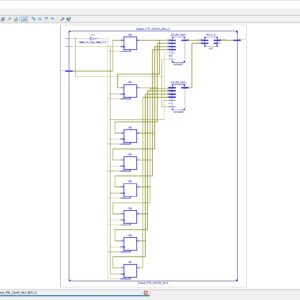
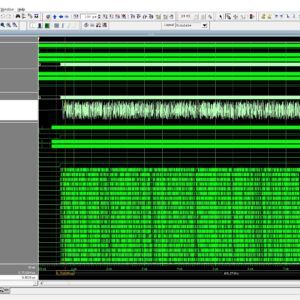
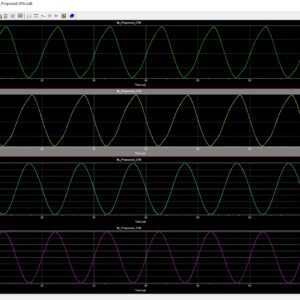
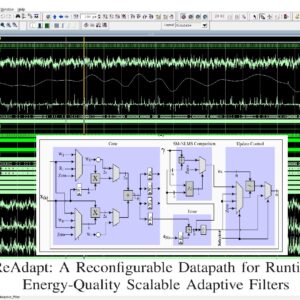
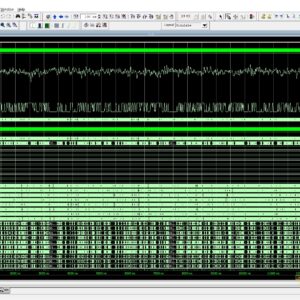
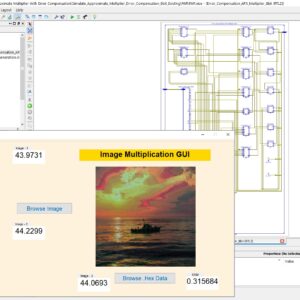
Check Recent 2023 Research Titles : Click Here
Choose any Titles, We can Develop it,..... !
IEEE Transactions on VLSI, VLSI IEEE Project, VLSI Low Power Project, VLSI High Speed Project, VLSI Area Efficient Project, Low Cost VLSI Projects, High Speed VLSI Design projects ( CDMA, RTOS, DSP, RF, IF, etc), Low Power VLSI Design projects, Area Efficient VLSI Design projects , Audio processing VLSI Design projects, Signal Processing VLSI Design projects, Image Processing VLSI Design projects, Backend VLSI Design projects ( CMOS, TFET, BisFET, FeFET, etc), Timing & Delay Reduction VLSI Projects, Internet of Things VLSI Projects, Testing, Reliability and Fault Tolerance VLSI Projects, VLSI Applications ( Communicational, Video, Security, Sensor Networks, etc), SOC VLSI Projects, Network on Chip VLSI Projects, Wireless Communication VLSI Projects, VLSI Verifications Projects ( UVM, OVM, VVM, System Verilog).

