
Fully Reused VLSI Architecture of FM0Manchester Encoding Using SOLS Technique for DSRC Applications
Original price was: ₹15,000.00.₹10,000.00Current price is: ₹10,000.00.
Source : VHDL
Abstract:
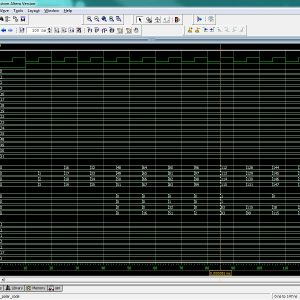
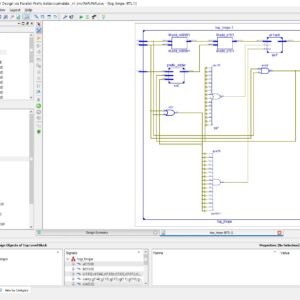
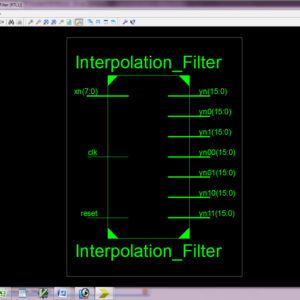
The dedicated short-range communication (DSRC) is an emerging technique to push the intelligent transportation system into our daily life. The DSRC standards generally adopt FM0 and Manchester codes to reach dc-balance, enhancing the signal reliability. Nevertheless, the coding-diversity between the FM0 and Manchester codes seriously limits the potential to design a fully reused VLSI architecture for both. In this paper, the similarity-oriented logic simplification (SOLS) technique is proposed to overcome this limitation. The encoding capability of this paper can fully support the DSRC standards of America, Europe, and Japan. This paper not only develops a fully reused VLSI architecture, but also exhibits an efficient performance compared with the existing works. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Proposed Title :
FPGA Implementation of Area Efficient Fully Reused FMOManchester with Comparison of FMOMiller Encoding using SOLS Technique for DSRC application
Proposed System:
- Provide the Comparison of FMO Manchester and FMO Miller Encoding
- Low Power and Area Efficient
Software implementation:
- XILINX – HDL Implementation
- Modelsim
Related products

 Fully Reused VLSI Architecture...
Fully Reused VLSI Architecture...
Original price was: ₹15,000.00.₹10,000.00Current price is: ₹10,000.00.
Reviews
There are no reviews yet.