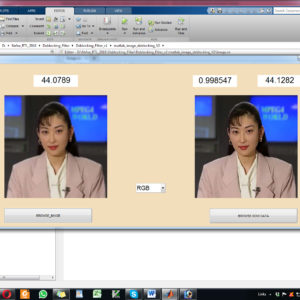
A Deblocking Filter Hardware Architecture for the High Efficiency Video Coding Standard
The new deblocking filter (DF) tool of the next generation High Efficiency Video Coding (HEVC) standard is one of the most time consuming algorithms in video decoding. In order to achieve real-time performance at low-power consumption, we developed a hardware accelerator for this filter. This paper proposes high throughput hardware architecture for HEVC deblocking filter employing hardware reuse to accelerate filtering decision units with a low area cost. Our architecture achieves either higher or equivalent throughput with 5X-6X lower area compared to state of-the-art deblocking filter architectures. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup: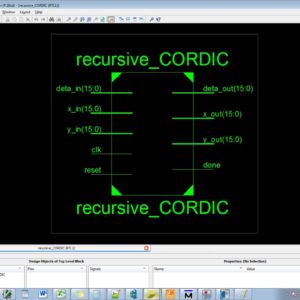
Concept Design and Implementation of Reconfigurable CORDIC
This brief presents the key concept, design strategy, and implementation of reconfigurable coordinate rotation digital computer (CORDIC) architectures that can be configured to operate either for circular or for hyperbolic trajectories in rotation as well as vectoring-modes. It can, therefore, be used to perform all the functions of both circular and hyperbolic CORDIC. We propose three reconfigurable CORDIC designs: 1) a reconfigurable rotation-mode CORDIC that operates either for circular or for hyperbolic trajectory; 2) a reconfigurable vectoring-mode CORDIC for circular and hyperbolic trajectories; and 3) a generalized reconfigurable CORDIC that can operate in any of the modes for both circular and hyperbolic trajectories. The reconfigurable CORDIC can perform the computation of various trigonometric and exponential functions, logarithms, square-root, and so on of circular and hyperbolic CORDIC using either rotation-mode or vectoring-mode CORDIC in one single circuit. It can be used in digital synchronizers, graphics processors, scientific calculators, and so on. It offers substantial saving of area complexity over the conventional design for reconfigurable applications. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
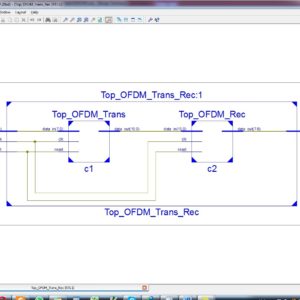
Design and Development of OFDM Baseband Transceiver using VIRTEX 6 FPGA Family
Broadband Wireless Access (BWA) is a successful technology which offers high speed voice, internet connection and video. One of the leading candidates for Broadband Wireless Access is Wi-MAX; it is a technology that compiles with the IEEE 802.16 family of standards. This paper mainly focused towards the hardware Implementation of Wireless MAN-OFDM Physical Layer of IEEE Std 802.16d Baseband Transceiver on FPGA. The RTL coding of VHDL was used, which provides a high level design-flow for developing and validating the communication system protocols and it provides flexibility of changes in future in order to meet real world performance evaluation. This proposed system is analysis area and power. Also the outputs are verified using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Design Methodology for Voltage Scaled Clock Distribution Networks
Abstract:
A low-voltage/swing clocking methodology is developed through both circuit and algorithmic innovations. The primary objective is to significantly reduce the power consumed by the clock network while maintaining the circuit performance the same. a novel D-flip-flop (DFF) cell that maximizes power savings by enabling low-voltage/swing operation throughout the entire clock network . In this proposed design of the LSFF is consume the less power compare to existing design. The proposed architecture of this paper is analysis the logic size, area and power consumption using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Design of Power and Area Efficient Approximate Multipliers
Abstract:
Approximate computing can decrease the design complexity with an increase in performance and power efficiency for error resilient applications. This brief deals with a new design approach for approximation of multipliers. The partial products of the multiplier are altered to introduce varying probability terms. Logic complexity of approximation is varied for the accumulation of altered partial products based on their probability. The proposed approximation is utilized in two variants of 16-bit multipliers. Synthesis results reveal that two proposed multipliers achieve power savings of 72% and 38%, respectively, compared to an exact multiplier. They have better precision when compared to existing approximate multipliers. Mean relative error figures are as low as 7.6% and 0.02% for the proposed approximate multipliers, which are better than the previous works. Performance of the proposed multipliers is evaluated with an image processing application, where one of the proposed models achieves the highest peak signal to noise ratio.
List of the following materials will be included with the Downloaded Backup:
Floating Point Butterfly Architecture Based on Binary Signed Digit Representation
Fast Fourier transform (FFT) coprocessor, having a significant impact on the performance of communication systems, has been a hot topic of research for many years. The FFT function consists of consecutive multiply add operations over complex numbers, dubbed as butterfly units. Applying floating-point (FP) arithmetic to FFT architectures, specifically butterfly units, has become more popular recently. It offloads compute-intensive tasks from general-purpose processors by dismissing FP concerns (e.g., scaling and overflow/underflow). However, the major downside of FP butterfly is its slowness in comparison with its fixed-point counterpart. This reveals the incentive to develop a high-speed FP butterfly architecture to mitigate FP slowness. This brief proposes a fast FP butterfly unit using a devised FP fused-dot product-add (FDPA) unit, to compute AB±CD±E, based on binary signed-digit (BSD) representation. The FP three-operand BSD adder and the FP BSD constant multiplier are the constituents of the proposed FDPA unit. A carry-limited BSD adder is proposed and used in the three-operand adder and the parallel BSD multiplier so as to improve the speed of the FDPA unit. Moreover, modified Booth encoding is used to accelerate the BSD multiplier. The synthesis results show that the proposed FP butterfly architecture is much faster than previous counterparts but at the cost of more area. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Glitch Energy Reduction and SFDR Enhancement Techniques for Low Power Binary Weighted Current Steering DAC
This brief proposes a glitch reduction approach by dynamic capacitance compensation of binary-weighted current switches in a current-steering digital-to-analog converter (DAC). The method was proved successfully by a 10-bit 400-MHz pure binary-weighted current steering DAC with a minimum number of retiming latches. The experiment results yield very low-glitch energy during major carry transitions at output.
List of the following materials will be included with the Downloaded Backup:
Input Based Dynamic Reconfiguration of Approximate Arithmetic Units for Video Encoding
Abstract:
The field of approximate computing has receivedsignificant attention from the research community in the pastfew years, especially in the context of various signal processingapplications. Image and video compression algorithms, such asJPEG, MPEG, and so on, are particularly attractive candidatesfor approximate computing, since they are tolerant of computingimprecision due to human imperceptibility, which can beexploited to realize highly power-efficient implementations ofthese algorithms. However, existing approximate architecturestypically fix the level of hardware approximation staticallyand are not adaptive to input data. For example, if afixed approximate hardware configuration is used for anMPEG encoder (i.e., a fixed level of approximation), theoutput quality varies greatly for different input videos. Thispaper addresses this issue by proposing a reconfigurableapproximate architecture for MPEG encoders thatoptimizespower consumption with the goal of maintaining a particularPeak Signal-to-Noise Ratio (PSNR) threshold for any video.We propose two heuristics for automaticallytuning the approximation degree of the RABs in thesetwo modules during runtime based on the characteristics of eachindividual video. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Low Power FPGA Design Using Memoization Based Approximate Computing
Field-programmable gate arrays (FPGAs) are increasingly used as the computing platform for fast and energy efficient execution of recognition, mining, and search applications. Approximate computing is one promising method for achieving energy efficiency. Compared with most prior works on approximate computing, which target approximate processors and arithmetic blocks, this paper presents an approximate computing methodology for FPGA-based design. It studies memoization as a method for approximation on FPGA and analyzes different architectural and design parameters that should be considered. The proposed design flow leverages on high-level synthesis to enable memoization-based microarchitecture generation, thus also facilitating a C-to-register-transfer-level synthesis. When compared with the previous approaches of bit-width truncation and approximate multipliers, memoization-based approximate computation on FPGA achieves a significant dynamic power saving (around 20%) with very small area overhead (<5%) and better power-to-signal noise ratio values for the studied image processing benchmarks. The proposed architecture of this paper is verified using vivado HLS..
List of the following materials will be included with the Downloaded Backup:
Low Power Split Radix FFT Processors Using Radix 2 Butterfly Units
Split radix fast Fourier Transform (SRFFT) is an ideal candidate for the implementation of a low power FFT processor, because it has the lowest number of arithmetic operation among all the FFT algorithms. In the design of such processors, an efficient addressing scheme for FFT data as well as twiddle factors is required. The signal flow graph of SRFFT is the same as radix-2 FFT, and therefore, the conventional address generation schemes of FFT data could also be applied to SRFFT. However SRFFT has irregular locations of twiddle factors and forbids the application of radix-2 address generation methods. This brief presents a shared memory low power SRFFT processor architecture. The SRFFT can be computed by using a modified radix-2 butterfly unit. The butterfly unit exploits the multiplier-gating technique to save dynamic power at the expense of using more hardware resources. In addition, two novel address generation algorithm for both the trivial and nontrivial twiddle factors are developed. In this paper We increases the architecture size, of radix-4 and 2048 point complex valued transform, and shown the performance of area, power and delay, and synthesized xilinx FPGA on s6lx16-2csg225.
List of the following materials will be included with the Downloaded Backup:
Low Power System for Detection of Symptomatic Patterns in Audio Biological Signals
We present a low-power, efficacious, and scalable system for the detection of symptomatic patterns in biological audio signals. The digital audio recordings of various symptoms, such as cough, sneeze, and so on, are spectrally analyzed using a discrete wavelet transform. Subsequently, we use simple mathematical metrics, such as energy, quasi-average, and coastline parameter for various wavelet coefficients of interest depending on the type of pattern to be detected. Furthermore, a mel-frequency cepstrum-based analysis is applied to distinguish between signals, such as cough and sneeze, which have a similar frequency response and, hence, occur in common wavelet coefficients. Algorithm-circuit codesign methodology is utilized in order to optimize the system at algorithm and circuit levels of design abstraction. This helps in implementing a low-power system as well as maintaining the efficacy of detection. The system is scalable in terms of user specificity as well as the type of signal to be analyzed for an audio symptomatic pattern. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Resource Efficient SRAM based Ternary Content Addressable Memory
Abstract:
Static random access memory (SRAM)-based ternary content addressable memory (TCAM) offers TCAM functionality by emulating it with SRAM. However, this emulation suffers from reduced memory efficiency while mapping the TCAM table on SRAM units. This is due to the limited capacity of the physical addresses in the SRAM unit. This brief offers a novel memory architecture called a resource-efficient SRAM-based TCAM (REST), which emulates TCAM functionality using optimal resources. The SRAM unit is divided into multiple virtual blocks to store the address information presented in the TCAM table. This approach virtually increases the overall address space of the SRAM unit, mapping a greater portion of the TCAM table in SRAM and increasing the overall emulated TCAM bits/SRAM at the cost of reduced throughput. A 72 × 28-bit REST consumes only one 36-kbit SRAM and a few distributed RAMs via implementation on a Xilinx Kintex-7 field-programmable gate array. It uses only 3.5% of the memory resources compared with a conventional SRAM-based TCAM (hybrid-partitioned TCAM).
List of the following materials will be included with the Downloaded Backup: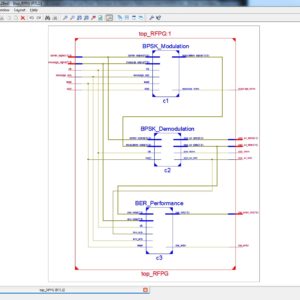
RF Power Gating A Low Power Technique for Adaptive Radios
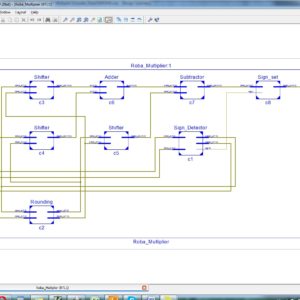
RoBA Multiplier A Rounding Based Approximate Multiplier for High Speed yet Energy Efficient Digital Signal Processing
Abstract:
In this paper, we propose an approximate multiplier that is high speed yet energy efficient. The approach is to round the operands to the nearest exponent of two. This way the computational intensive part of the multiplication is omitted improving speed and energy consumption at the price of a small error. The proposed approach is applicable to both signed and unsigned multiplications. We propose three hardware implementations of the approximate multiplier that includes one for the unsigned and two for the signed operations. The efficiency of the proposed multiplier is evaluated by comparing its performance with those of some approximate and accurate multipliers using different design parameters. In addition, the efficacy of the proposed approximate multiplier is studied in two image processing applications, i.e., image sharpening and smoothing.
List of the following materials will be included with the Downloaded Backup: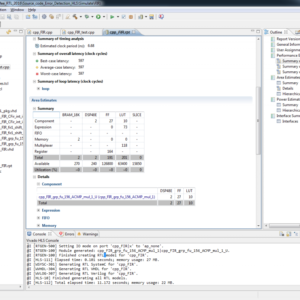
Source Code Error Detection in High Level Synthesis Functional Verification
A dynamic functional verification method that compares untimed simulations versus timed simulations for synthesizable [high-level synthesis (HLS)] behavioral descriptions (ANSI-C) is presented in this paper. This paper proposes a method that automatically inserts a set of probes into the untimed behavioral description. These probes record the status of internal signals of the behavioral description during an initial untimed simulation. These simulation results are subsequently used as golden outputs for the verification of the internal signals during a timed simulation once the behavioral description has been synthesized using HLS. Our proposed method reports any simulation mismatches and accurately pinpoints any discrepancies between the functional Software (SW) simulation and the timed simulation at the original behavioral description (source code). Our method does not only determine where to place the probes, but is also able to insert different type of probes based on the specified HLS synthesis options in order not to interfere with the HLS process, minimizing the total number of probes and the size of the data to be stored in the trace file in order to minimize the running time. Results show that our proposed method is very effective and extremely simple to use as it is fully automated using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
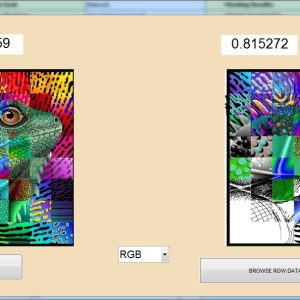
VLSI Implementation of an Edge-Oriented Image Scaling Processor
Abstract:
Image scaling is a very important technique and has been widely used in many image processing applications. In this paper, we present an edge-oriented area-pixel scaling processor. To achieve the goal of low cost, the area-pixel scaling technique is implemented with a low-complexity VLSI architecture in our design. A simple edge catching technique is adopted to preserve the image edge features effectively so as to achieve better image quality. Compared with the previous low-complexity techniques, our method performs better in terms of both quantitative evaluation and visual quality. The seven-stage VLSI architecture of our image scaling processor contains 10.4-K gate counts and yields a processing rate of about 200 MHz by using TSMC 0.18- m technology.
List of the following materials will be included with the Downloaded Backup:Provide Wordlwide Online Support
We can provide Online Support Wordlwide, with proper execution, explanation and additionally provide explanation video file for execution and explanations.
24/7 Support Center
NXFEE, will Provide on 24x7 Online Support, You can call or text at +91 9789443203, or email us nxfee.innovation@gmail.com
Terms & Conditions:
Customer are advice to watch the project video file output, and before the payment to test the requirement, correction will be applicable.
After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
Online support will not be given more than 3 times.
On first time explanation we can provide completely with video file support, other 2 we can provide doubt clarifications only.
If any Issue on Software license / System Error we can support and rectify that within end of day.
Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
After payment, to must send the payment receipt to our email id.
Powered by NXFEE INNOVATION, Pondicherry.
Call us today at : +91 9789443203 or Email us at nxfee.innovation@gmail.com
NXFEE Development & Services

Copyright © 2026 Nxfee Innovation.