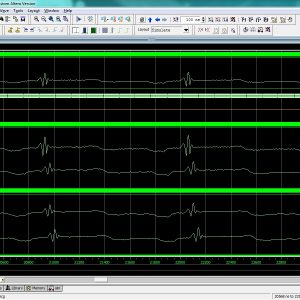
Low Power ECG Based Processor for Predicting Ventricular Arrhythmia
This paper presents the design of a fully integrated electrocardiogram (ECG) signal processor (ESP) for the prediction of ventricular arrhythmia using a unique set of ECG features and a naive Bayes classifier. Real-time and adaptive techniques for the detection and the delineation of the P-QRS-T waves were investigated to extract the fiducial points. We are also detecting the all interval in the ECG signal and compare the stored record for Ventricular Arrhythmia with also energy/area architecture design. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Low-Energy Power-ON-Reset Circuit for Dual Supply SRAM
Design of a low-energy power-ON reset (POR) circuit is proposed to reduce the energy consumed by the stable supply of the dual supply static random access memory (SRAM), as the other supply is ramping up. The proposed POR circuit, when embedded inside dual supply SRAM, removes its ramp-up constraints related to voltage sequencing and pin states. The circuit consumes negligible energy during ramp-up, does not consume dynamic power during operations, and includes hysteresis to improve noise immunity against voltage fluctuations on the power supply. The POR circuit, designed in the 40-nm CMOS technology within 10.6-µm2 area, enabled 27× reduction in the energy consumed by the SRAM array supply during periphery power-up in typical conditions. The proposed architecture of this paper area and power consumption analysis using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Low-Power and Fast Full Adder by Exploring New XOR and XNOR Gates
Abstract:
In this paper, novel circuits for XOR/XNOR and simultaneous XOR–XNOR functions are proposed. The proposed circuits are highly optimized in terms of the power consumption and delay, which are due to low output capacitance and low short-circuit power dissipation. We also propose six new hybrid 1-bit full-adder (FA) circuits based on the novel full-swing XOR–XNOR or XOR/XNOR gates. Each of the proposed circuits has its own merits in terms of speed, power consumption, power delay product (PDP), driving ability, and so on. To investigate the performance of the proposed designs, extensive HSPICE and Cadence Virtuoso simulations are performed. The simulation results, based on the 65-nm CMOS process technology model, indicate that the proposed designs have superior speed and power against other FA designs. A new transistor sizing method is presented to optimize the PDP of the circuits. In the proposed method, the numerical computation particle swarm optimization algorithm is used to achieve the desired value for optimum PDP with fewer iterations. The proposed circuits are investigated in terms of variations of the supply and threshold voltages, output capacitance, input noise immunity, and the size of transistors.
List of the following materials will be included with the Downloaded Backup: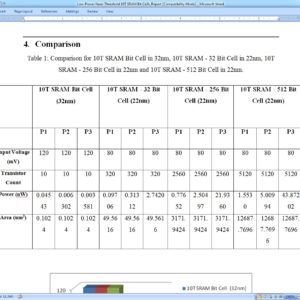
Low-Power Near-Threshold 10T SRAM Bit Cells With Enhanced Data-Independent Read Port Leakage for Array Augmentation in 32-nm CMOS
Abstract:
The conventional six-transistor static random access memory (SRAM) cell allows high density and fast differential sensing but suffers from half-select and read-disturb issues. Although the conventional eight-transistor SRAM cell solves the read-disturb issue, it still suffers from low array efficiency due to deterioration of read bit-line (RBL) swing and Ion/Ioff ratio with increase in the number of cells per column. Previous approaches to solve these issues have been afflicted by low performance, data dependent leakage, large area, and high energy per access. Therefore, in this paper, we present three iterations of SRAM bit cells with nMOS-only based read ports aimed to greatly reduce data dependent read port leakage to enable 1k cells/RBL, improve read performance, and reduce area and power over conventional and 10T cell-based works. We compare the proposed work with other works by recording metrics from the simulation of a 128-kb SRAM constructed with divided-word line-decoding architecture and a 32-bit word size. Apart from large improvements observed over conventional cells, up to 100-mV improvement in read-access performance, up to 19.8% saving in energy per access, and up to 19.5% saving in the area are also observed over other 10T cells, thereby enlarging the design and application gamut for memory designers in low-power sensors and battery-enabled devices.
List of the following materials will be included with the Downloaded Backup:
Low-Voltage Bandgap Reference Circuit in 28nm CMOS
Abstract:
This paper presents a hybrid adjusted temperature compensation circuit for reducing the temperature drift of the bandgap reference. Combining first-order bandgap current, nonlinear compensation current, and temperature curvature compensation current together, a temperature insensitive reference voltage can be obtained in proposed circuit. Designed and verified in UMC 28nm CMOS technology with Cadence IC615, the proposed circuit achieves a post-layout simulation temperature drift of 5.48 ppm/°C in the range of -20°C to 120°C with a supply voltage of 1.05-V.
List of the following materials will be included with the Downloaded Backup: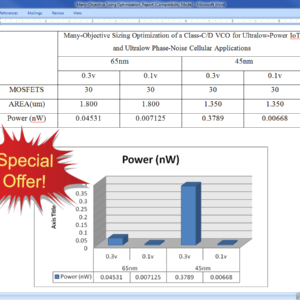
Many-Objective Sizing Optimization of a Class-C/D VCO for Ultralow-Power IoT and Ultralow Phase-Noise Cellular Applications
Abstract:
In this paper, the performance boundaries and corresponding tradeoffs of a complex dual-mode class-C/D voltage controlled oscillator (VCO) are extended using a framework for the automatic sizing of radio frequency integrated circuit blocks, where an all-inclusive test bench formulation enhanced with an additional measurement processing system enables the optimization of “everything at once” toward its true optimal tradeoffs. VCOs embedded in the state-of-the-art multi standard transceivers must comply with extremely high performance and ultralow power requirements for modern cellular and Internet of Things applications. However, the proper analysis of the design tradeoffs is tedious and impractical, as a large amount of conflicting performance figures obtained from multiple modes, test benches, and/or analysis must be considered simultaneously. Here, the dual-mode design and optimization conducted provided 287 design solutions with figures of merit above 192 dBc/Hz, where the power consumption varies from 0.134 to 1.333 mW, the phase noise at 10 MHz from −133.89 to −142.51 dBc/Hz, and the frequency pushing from 2 to 500 MHz/V, on the worst case of the tuning range. These results pushed this circuit design to its performance limits on a 65-nm CMOS technology, reducing 49% of the power consumption of the original design while also showing its potential for ultralow power with more than 93% reduction. In addition, worst case corner criteria were also performed on the top of the worst case tuning range optimization, taking the problem to a human-untrea table LXVI-D performance space.
List of the following materials will be included with the Downloaded Backup:
Multiloop Control for Fast Transient DC–DC Converter
Abstract:
A novel ac coupled feedback (ACCF) is proposed to alternatively realize fast transient response while inherently controlling the start-up in-rush current of a dc–dc switching converter. The proposed ACCF is modified from a conventional capacitor multiplier and connected between the outputs of the converter and the transconductance. With this supplemental feedback, the transient response has been significantly improved due to the gain-boosting effect around the compensator’s midband. Moreover, the ACCF circuit assists to manage the ramping speed of the output voltage during power-up, thereby eliminating the bulky soft-start circuit. The new controller is very simple to implement and occupies a tiny footprint on-chip. A buck converter with the proposed scheme has been fabricated using the 0.18-µm standard CMOS process with an active silicon area of 0.573 mm2. Measurement results show that the output voltage rises linearly for a soft-start period of 1.05 ms according to the designed slope. Excellent load transient responses are achieved under different load current steps; the output voltage overshoot/undershoot of 60 mV settles down within 10 µs for a load variation from 50 µA to 1 A in 1 µs. Moreover, the proposed converter maintains both excellent load and line regulations of 0.018 mV/mA and 0.0056 mV/mV, respectively.
List of the following materials will be included with the Downloaded Backup:
One-Sided Schmitt-Trigger-Based 9T SRAM Cell for Near-Threshold Operation
Abstract:
This paper presents a one-sided Schmitt-trigger based 9T static random access memory cell with low energy consumption and high read stability, write ability, and hold stability yields in a bit-interleaving structure without write-back scheme. The proposed Schmitt-trigger-based 9T static random access memory cell obtains a high read stability yield by using a one-sided Schmitt-trigger inverter with a single bit-line structure. In addition, the write ability yield is improved by applying selective power gating and a Schmitt-trigger inverter write assist technique that controls the trip voltage of the Schmitt-trigger inverter. The proposed Schmitt-trigger-based 9T static random access memory cell has 0.79, 0.77, and 0.79 times the area, and consumes 0.31, 0.68, and 0.90 times the energy of Chang’s 10T, the Schmitt-trigger-based 10T, and MH’s 9T static random access memory cells, respectively, based on 22-nm Fin FET technology.
List of the following materials will be included with the Downloaded Backup:
Quaternary Logic Lookup Table in Standard CMOS
Abstract: Interconnections are increasingly the dominant contributor to delay, area and energy consumption in CMOS digital circuits. The proposed implementation overcomes several limitations found in previous quaternary implementations published so far, such as the need for special features in the CMOS process or power-hungry current-mode cells. We have to use the 512bit quaternary Look Up Table for high level of operations in the FPGA.The proposed architecture of this paper will be planned to implemented and also analysis the output current, output voltage, area using Xilinx 14.3.
List of the following materials will be included with the Downloaded Backup:
Radiation-Hardened 0.3–0.9-V Voltage-Scalable 14T SRAM and Peripheral Circuit in 28-nm Technology for Space Applications
Abstract:
Conventional radiation-hardened cells of static random access memory (SRAM) are not robust enough in 28 nm technology, due to partial immunity of single-event upset (SEU) effect (Quatrobased cells) or insufficient critical charges in sensitive nodes (conventional stacked cells). The reduction of read noise margin (RNM) at the low supply voltage (VDD) confines these cells from low VDD applications. We propose a novel interleaving stacked-14T (ILS-14T) cell which prevents voltage transient from propagating to other redundancies. The ILS-14T cell can be resilient to both 0–1 and 1–0 upsets by injecting 12 mA in sensitive nodes. The critical charges of the ILS-14T cell are substantially larger than most other hardened cells at VDD from 0.3 to 0.9 V. The RNM of the ILS-14T cell is two times of most Quatro-based cells at 0.3 V VDD and larger than most cells at 0.6 and 0.9 V VDD. The area of occupation is 334% of the conventional 6T cell, which equals other 14T cells. The static–dynamic decoder array with 20%–40% area penalty and 116%–132% delay of rising edge, when compared with the conventional one, reduces the read failure rate by preventing single event transients (SETs) from propagating to unexpected word lines (WLs).
List of the following materials will be included with the Downloaded Backup:
Radiation-Hardened 14T SRAM Bit cell With Speed and Power Optimized for Space Application
Abstract:
In this paper, a novel radiation-hardened 14-transistor SRAM bit cell with speed and power optimized [radiation-hardened with speed and power optimized (RSP)-14T] for space application is proposed. By circuit- and layout-level optimization design in a 65-nm CMOS technology, the 3-D TCAD mixed-mode simulation results show that the novel structure is provided with increased resilience to single-event upset as well as single-event–multiple-node upsets due to the charge sharing among OFF-transistors. Moreover, the HSPICE simulation results show that the write speed and power consumption of the proposed RSP-14T are improved by ∼65% and ∼50%, respectively, compared with those of the radiation hardened design (RHD)-12T memory cell.
List of the following materials will be included with the Downloaded Backup:
RandShift: An Energy-Efficient Fault Tolerant Method in Secure Nonvolatile Main Memory
Abstract:
In this article, we present a simple, yet energy- and area-efficient method for tolerating the stuck-at faults caused by an endurance issue in secure-resistive main memories. In the proposed method, by employing the random characteristics of the encrypted data encoded by the Advanced Encryption Standard (AES) as well as a rotational shift operation, a large number of memory locations with stuck-at faults could be employed for correctly storing the data. Due to the simple hardware implementation of the proposed method, its energy consumption is considerably smaller than that of other recently proposed methods. The technique may be employed along with other error correction methods, including the error correction code (ECC) and the error correction pointer (ECP). To assess the efficacy of the proposed method, it is implemented in a phase-change memory (PCM)- based main memory system and compared with three error tolerating methods. The results reveal that for a stuck-at fault occurrence rate of 10−2 and with the uncorrected bit error rate of 2 × 10−3, the proposed method achieves 82% energy reduction compared to the state-of-the-art method. More generally, using a simulation analysis technique, we show that the fault coverage of the proposed method is similar to that of the state-of-the-art method.
List of the following materials will be included with the Downloaded Backup: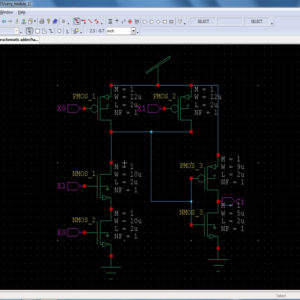
Recursive Approach to the Design of a Parallel Self Timed Adder
Abstract: We are briefly discussed about the 64bit parallel self timed adder based on the recursive formulation. The adder is also based on the asynchronous logic circuit and the transistor is connected in parallel. This adder is chance the path automatically, so the delay is configures automatically. The completion detection unit is given the additional support for practical implementation. The simulation is take place with 130nm CMOS technology for the adder circuit. Finally the power consumption for 64bit adder is 0.29mW.
List of the following materials will be included with the Downloaded Backup: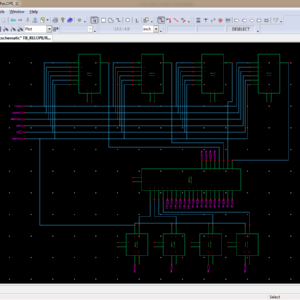
ReLOPE: Resistive RAM-Based Linear First-Order Partial Differential Equation Solver
Abstract:
Data movement between memory and processing units poses an energy barrier to Von-Neumann-based architectures. In-memory computing (IMC) eliminates this barrier. RRAM-based IMC has been explored for data-intensive applications, such as artificial neural networks and matrix-vector multiplications that are considered as “soft” tasks where performance is a more important factor than accuracy. In “hard” tasks such as partial differential equations (PDEs), accuracy is a determining factor. In this brief, we propose ReLOPE, a fully RRAM crossbar-based IMC to solve PDEs using the Runge–Kutta numerical method with 97% accuracy. ReLOPE expands the operating range of solution by exploiting shifters to shift input data and output data. ReLOPE range of operation and accuracy can be expanded by using fine-grained step sizes by programming other RRAMs on the BL. Compared to software-based PDE solvers, ReLOPE gains 31.4× energy reduction at only 3% accuracy loss.
List of the following materials will be included with the Downloaded Backup: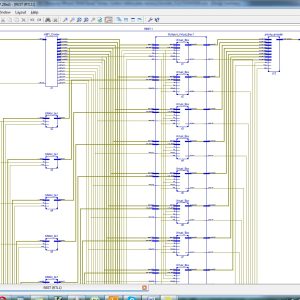
Resource Efficient SRAM based Ternary Content Addressable Memory
Abstract:
Static random access memory (SRAM)-based ternary content addressable memory (TCAM) offers TCAM functionality by emulating it with SRAM. However, this emulation suffers from reduced memory efficiency while mapping the TCAM table on SRAM units. This is due to the limited capacity of the physical addresses in the SRAM unit. This brief offers a novel memory architecture called a resource-efficient SRAM-based TCAM (REST), which emulates TCAM functionality using optimal resources. The SRAM unit is divided into multiple virtual blocks to store the address information presented in the TCAM table. This approach virtually increases the overall address space of the SRAM unit, mapping a greater portion of the TCAM table in SRAM and increasing the overall emulated TCAM bits/SRAM at the cost of reduced throughput. A 72 × 28-bit REST consumes only one 36-kbit SRAM and a few distributed RAMs via implementation on a Xilinx Kintex-7 field-programmable gate array. It uses only 3.5% of the memory resources compared with a conventional SRAM-based TCAM (hybrid-partitioned TCAM).
List of the following materials will be included with the Downloaded Backup: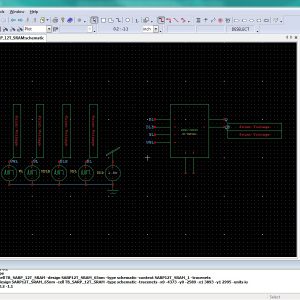
Soft-Error-Aware Read-Stability-Enhanced Low-Power 12T SRAM With Multi-Node Upset Recoverability for Aerospace Applications
Abstract:
With the advancement of technology, the size of transistors and the distance between them are reducing rapidly. Therefore, the critical charge of sensitive nodes is reducing, making SRAM cells, used for aerospace applications, more vulnerable to soft-error. If a radiation particle strikes a sensitive node of the standard 6T SRAM cell, the stored data in the cell are flipped, causing a single-event upset (SEU). Therefore, in this paper, a Soft-Error-Aware Read-Stability-Enhanced Low Power 12T (SARP12T) SRAM cell is proposed to mitigate SEUs. To analyze the relative performance of SARP12T, it is compared with other recently published soft-error-aware SRAM cells, QUCCE12T, QUATRO12T, RHD12T, RHPD12T and RSP14T. All the sensitive nodes of SARP12T can regain their data even if the node values are flipped due to a radiation strike. Furthermore, SARP12T can recover from the effect of single event multi-node upsets (SEMNUs) induced at its storage node pair. Along with these advantages, the proposed cell exhibits the highest read stability, as the ‘0’-storing storage node, which is directly accessed by the bit line during read operation, can recover from any upset. Furthermore, SARP12T consumes the least hold power. SARP12T also exhibits higher write ability and shorter write delay than most of the comparison cells. All these improvements in the proposed cell are obtained by exhibiting only a slightly longer read delay and consuming slightly higher read and write energy.
List of the following materials will be included with the Downloaded Backup:
Source Code Error Detection in High Level Synthesis Functional Verification
A dynamic functional verification method that compares untimed simulations versus timed simulations for synthesizable [high-level synthesis (HLS)] behavioral descriptions (ANSI-C) is presented in this paper. This paper proposes a method that automatically inserts a set of probes into the untimed behavioral description. These probes record the status of internal signals of the behavioral description during an initial untimed simulation. These simulation results are subsequently used as golden outputs for the verification of the internal signals during a timed simulation once the behavioral description has been synthesized using HLS. Our proposed method reports any simulation mismatches and accurately pinpoints any discrepancies between the functional Software (SW) simulation and the timed simulation at the original behavioral description (source code). Our method does not only determine where to place the probes, but is also able to insert different type of probes based on the specified HLS synthesis options in order not to interfere with the HLS process, minimizing the total number of probes and the size of the data to be stored in the trace file in order to minimize the running time. Results show that our proposed method is very effective and extremely simple to use as it is fully automated using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:

To develop and Implement Low Power, High Speed VLSI for Processing Signals using Multi rate Techniques Low Power Divider Using Vedic Mathematics
Abstract:
Multirate technique is necessary for systems with different input and output sampling rates. Recent advances in mobile computing and communication applications demand low power and high speed VLSI DSP systems. In this paper to discuss the downsampling technique and its improvement, major drawbacks of present approaches possible to increase degeneracy. This Multirate design methodology is systematic and applicable to many problems. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
TOSAM: An Energy-Efficient Truncation- and Rounding-Based Scalable Approximate Multiplier
Abstract:
A scalable approximate multiplier, called truncation- and rounding-based scalable approximate multiplier (TOSAM) is presented, which reduces the number of partial products by truncating each of the input operands based on their leading one-bit position. In the proposed design, multiplication is performed by shift, add, and small fixed-width multiplication operations resulting in large improvements in the energy consumption and area occupation compared to those of the exact multiplier. To improve the total accuracy, input operands of the multiplication part are rounded to the nearest odd number. Because input operands are truncated based on their leading one-bit positions, the accuracy becomes weakly dependent on the width of the input operands and the multiplier becomes scalable. Higher improvements in design parameters (e.g., area and energy consumption) can be achieved as the input operand widths increase. To evaluate the efficiency of the proposed approximate multiplier, its design parameters are compared with those of an exact multiplier and some other recently proposed approximate multipliers. Results reveal that the proposed approximate multiplier with a mean absolute relative error in the range of 11%–0.3% improves delay, area, and energy consumption up to 41%, 90%, and 98%, respectively, compared to those of the exact multiplier. It also outperforms other approximate multipliers in terms of speed, area, and energy consumption. The proposed approximate multiplier has an almost Gaussian error distribution with a near-zero mean value. We exploit it in the structure of a JPEG encoder, sharpening, and classification applications. The results indicate that the quality degradation of the output is negligible. In addition, we suggest an accuracy configurable TOSAM where the energy consumption of the multiplication operation can be adjusted based on the minimum required accuracy.
List of the following materials will be included with the Downloaded Backup:
Two-Stage OTA With All Subthreshold MOSFETs and Optimum GBW to DC-Current Ratio
Base Paper Abstract:
An approach for the design of two-stage class AB OTAs with sub-1µA current consumption is proposed and demonstrated. The approach employs MOS transistors operating in subthreshold and allows maximum gain-bandwidth product (GBW) to be achieved for a given DC current budget, by setting optimum distribution of DC currents in the two amplifier stages. Following this strategy, a class AB OTA was designed in a standard 0.5-µm CMOS technology supplied from 1.6-V and experimentally tested. Measured GBW was 307 kHz with 980-nA DC current consumption while driving an output capacitance of 40 pF with an average slew rate of 96 V/ms.
List of the following materials will be included with the Downloaded Backup:
Vital-Sign Processing Receiver With Clutter Elimination Using Servo Feedback Loop for UWB Pulse Radar System
Abstract:
This brief presents a vital-sign processing circuit for simultaneous dc/near-dc elimination and out-of-band interference rejection without any digital signal processing or algorithm assistance for the ultra wideband (UWB) pulse-based radar system. An intrinsic self balanced MOS diode (SBMD) was proposed as a stable and balanced pseudo resistor applied under a servo feedback loop in a vital-sign receiver of the sensing radar to perform as a high-pass filter (HPF) with an ultralow corner frequency lower than 0.5 Hz for removing undesired clutters of the reflected signals and input dc-offset voltages from innate circuit offsets. A third-order switched-capacitor (SC) Chebyshev low-pass filter (LPF) with leap-frog topology as the subsequent stage was adopted to suppress the out-band noises, thereby establishing an integrated vital-sign processing circuit with band pass frequency response and incorporating it into a radar module to verify its viability.
List of the following materials will be included with the Downloaded Backup:Provide Wordlwide Online Support
We can provide Online Support Wordlwide, with proper execution, explanation and additionally provide explanation video file for execution and explanations.
24/7 Support Center
NXFEE, will Provide on 24x7 Online Support, You can call or text at +91 9789443203, or email us nxfee.innovation@gmail.com
Terms & Conditions:
Customer are advice to watch the project video file output, and before the payment to test the requirement, correction will be applicable.
After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
Online support will not be given more than 3 times.
On first time explanation we can provide completely with video file support, other 2 we can provide doubt clarifications only.
If any Issue on Software license / System Error we can support and rectify that within end of day.
Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
After payment, to must send the payment receipt to our email id.
Powered by NXFEE INNOVATION, Pondicherry.
Call us today at : +91 9789443203 or Email us at nxfee.innovation@gmail.com
NXFEE Development & Services

Product Categories
- 2014 (12)
- 2015 (39)
- 2016 (31)
- 2017 (16)
- 2018 (17)
- 2019 (42)
- 2020 (29)
- 2021 (16)
- 2022 (22)
- 2023 (17)
- Area Efficient (92)
- High speed VLSI Design (49)
- IEEE (16)
- Image Processing (34)
- Low power VLSI Design (71)
- NOC VLSI Design (3)
- VLSI (180)
- VLSI Application / Interface and Mini Projects (13)
- VLSI_2023 (15)
Filter by price
Product Status
Sort by producents

Copyright © 2021 Nxfee Innovation.