Low-Power and High-Speed SRAM Cells With Double-Node Upset Self-Recovery for Reliable Applications
Transistor sizing and spacing are constantly decreasing due to the continuous advancement of CMOS technology. The charge of the sensitive nodes in the static random access memory (SRAM) cell gradually decreases, making the SRAM cell more and more sensitive to soft errors, such as single node upsets (SNUs) and double node upsets (DNUs). Therefore, two types of radiation-hardened SRAM cells are proposed in this article. First, a low-power DNU self-recovery S6P8N cell is proposed. This cell can realize SNU self-recovery from all sensitive nodes as well as realize partial DNUs self-recovery and has low-power consumption overhead. Second, we propose a high-speed DNU self-recovery S8P6N cell, which has a soft-error tolerance level similar to the S6P8N. Furthermore, it reduces the read access time (RAT) and write access time (WAT). Simulation results show that the proposed cells are self-recovery for all SNUs and most of DNUs. Compared with RHD12, QCCM12T, QUCCE12T, RHMD10T, SEA14T, RHM-12T, S4P8N, S8P4N, RH-14T, HRLP16T, CC18T, and RHM, the average power consumption of S6P8N is reduced by 48.78%, and the average WAT is reduced by 6.62%. While the average power consumption of S8P6N is reduced by 23.64%, and the average WAT and RAT by 9.07% and 36.84%, respectively. Index Terms: Double-node upsets (DNUs), high-speed, low power, self-recovery, static random access memory (SRAM).
List of the following materials will be included with the Downloaded Backup:
Low-Power Approximate Unsigned Multipliers with Configurable Error Recovery
Abstract:
Approximate circuits have been considered for applications that can tolerate some loss of accuracy with improved performance and/or energy efficiency. Multipliers are key arithmetic circuits in many of these applications including digital signal processing (DSP). In this paper, a novel approximate multiplier with a low power consumption and a short critical path is proposed for high-performance DSP applications. This multiplier leverages a newly designed approximate adder that limits its carry propagation to the nearest neighbors for fast partial product accumulation. Different levels of accuracy can be achieved by using either OR gates or the proposed approximate adder in a configurable error recovery. The multipliers using these two error reduction strategies are referred to as approximate multiplier 1 (AM1) and approximate multiplier 2 (AM2), respectively. Both AM1 and AM2 have a low mean error distance, i.e., most of the errors are not significant in magnitude. Compared to a Wallace multiplier optimized for speed, an 8×8 AM1 with 4 MSBs (most significant bits) for error reduction and synthesized using a 28 nm CMOS process shows a 60% reduction in delay (when optimized for delay) and a 42% reduction in power dissipation (when optimized for area). In a 16×16 design, half of the least significant partial products are truncated for AM1 and AM2, which are thus denoted as TAM1 and TAM2, respectively. Compared with the Wallace multiplier, TAM1 and TAM2 save from 50% to 66% in power, when optimized for area. Compared to existing approximate multipliers, AM1, AM2, TAM1 and TAM2 show significant advantages in accuracy with a high performance. AM2 has a better accuracy compared to AM1 but with a longer delay and higher power consumption. Image processing applications including image sharpening and smoothing are considered to show the quality of the approximate multipliers in error-tolerant applications. By utilizing an appropriate error recovery, the proposed approximate multipliers achieve similar processing accuracy as traditional exact multipliers, but with significant improvements in power.
List of the following materials will be included with the Downloaded Backup:
Low-Power High Precision Floating-Point Divider with Bidimensional Linear Approximation
Base Paper Abstract:
In this paper we propose a novel approximate floating-point divider based on bi-dimensional linear approximation. In our approach, the mantissa quotient is seen as a function of the two input mantissas of the divider. The domain of this two-variable function is partitioned into nx × ny subregions, named tiles, where nx, ny are chosen as powers of two. In each tile the quotient is approximated with a linear combination of the input mantissas. To achieve fine accuracy, an optimization problem is formulated within each tile to determine the optimal coefficients for the linear combination, which minimize the Mean Relative Error Distance (MRED) of the divider. Furthermore, to make hardware implementation more effective, the minimization problem is appropriately modified to search for optimal quantized coefficients. The hardware structure of the divider only requires a small look-up table to store the linear approximation coefficients, and a carry save adder tree. The proposed architecture is highly tunable at design-time over a wide range of accuracy, depending on the number of tiles chosen for the approximation. The obtained results demonstrate error performance and hardware features superior to the state-of-the-art. The proposed dividers define the Pareto front, considering the trade-off between power-delay-product vs. MRED and area-delay-product vs. MRED, for MRED in the range of 4 × 10−3 − 2 × 10−2. Application results for JPEG compression and tone mapping further highlight the strength of our proposal, which exhibits Structural Similarity Index (SSIM) very close to 1 in all cases and Peak Signal-to-Noise Ratio (PSNR) up to 45 db. Index Terms: Floating-point divider, approximate computing, error correction, low-power.
List of the following materials will be included with the Downloaded Backup: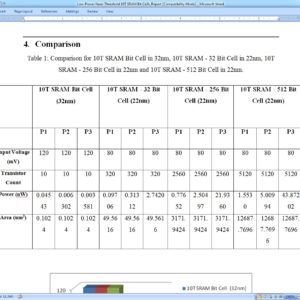
Low-Power Near-Threshold 10T SRAM Bit Cells With Enhanced Data-Independent Read Port Leakage for Array Augmentation in 32-nm CMOS
Abstract:
The conventional six-transistor static random access memory (SRAM) cell allows high density and fast differential sensing but suffers from half-select and read-disturb issues. Although the conventional eight-transistor SRAM cell solves the read-disturb issue, it still suffers from low array efficiency due to deterioration of read bit-line (RBL) swing and Ion/Ioff ratio with increase in the number of cells per column. Previous approaches to solve these issues have been afflicted by low performance, data dependent leakage, large area, and high energy per access. Therefore, in this paper, we present three iterations of SRAM bit cells with nMOS-only based read ports aimed to greatly reduce data dependent read port leakage to enable 1k cells/RBL, improve read performance, and reduce area and power over conventional and 10T cell-based works. We compare the proposed work with other works by recording metrics from the simulation of a 128-kb SRAM constructed with divided-word line-decoding architecture and a 32-bit word size. Apart from large improvements observed over conventional cells, up to 100-mV improvement in read-access performance, up to 19.8% saving in energy per access, and up to 19.5% saving in the area are also observed over other 10T cells, thereby enlarging the design and application gamut for memory designers in low-power sensors and battery-enabled devices.
List of the following materials will be included with the Downloaded Backup:
Low-Power, Low-Energy, Static, Contention-Free, TSPC Dual-Edge Triggered Flip-Flops
Base Paper Abstract:
The dual edge-triggered flip-flop samples the data on both the positive and negative edges of the clock. Hence, it can lead to lower clock relative power consumption as compared to the single-edge triggered flip-flop while maintaining the same data throughput. In this paper, we present two low-power, low-energy dual-edge triggered TSPC flip-flops based on latch-mux type methodology. These two flip-flops, Low-Power at Low Data Activity (LPLD-DET), and Low-Power at High Data Activity (LPHD-DET) are suitable for low-power application. These flip-flops are fully static and contention-free. The post-layout simulation results in TSMC CMOS 65 nm technology suggest that the proposed LPLD-DET is the most power-efficient dual-edge triggered flip-flop for low data activities up to 30%, and LPHD-DET is the most power-efficient dual-edge triggered flip-flop for higher data activities from 45% compared to the other state of-the-art dual-edge triggered TSPC flip-flops.
List of the following materials will be included with the Downloaded Backup:
Low-Voltage Bandgap Reference Circuit in 28nm CMOS
Abstract:
This paper presents a hybrid adjusted temperature compensation circuit for reducing the temperature drift of the bandgap reference. Combining first-order bandgap current, nonlinear compensation current, and temperature curvature compensation current together, a temperature insensitive reference voltage can be obtained in proposed circuit. Designed and verified in UMC 28nm CMOS technology with Cadence IC615, the proposed circuit achieves a post-layout simulation temperature drift of 5.48 ppm/°C in the range of -20°C to 120°C with a supply voltage of 1.05-V.
List of the following materials will be included with the Downloaded Backup:
Many-Objective Sizing Optimization of a Class-C/D VCO for Ultralow-Power IoT and Ultralow Phase-Noise Cellular Applications
Abstract:
In this paper, the performance boundaries and corresponding tradeoffs of a complex dual-mode class-C/D voltage controlled oscillator (VCO) are extended using a framework for the automatic sizing of radio frequency integrated circuit blocks, where an all-inclusive test bench formulation enhanced with an additional measurement processing system enables the optimization of “everything at once” toward its true optimal tradeoffs. VCOs embedded in the state-of-the-art multi standard transceivers must comply with extremely high performance and ultralow power requirements for modern cellular and Internet of Things applications. However, the proper analysis of the design tradeoffs is tedious and impractical, as a large amount of conflicting performance figures obtained from multiple modes, test benches, and/or analysis must be considered simultaneously. Here, the dual-mode design and optimization conducted provided 287 design solutions with figures of merit above 192 dBc/Hz, where the power consumption varies from 0.134 to 1.333 mW, the phase noise at 10 MHz from −133.89 to −142.51 dBc/Hz, and the frequency pushing from 2 to 500 MHz/V, on the worst case of the tuning range. These results pushed this circuit design to its performance limits on a 65-nm CMOS technology, reducing 49% of the power consumption of the original design while also showing its potential for ultralow power with more than 93% reduction. In addition, worst case corner criteria were also performed on the top of the worst case tuning range optimization, taking the problem to a human-untrea table LXVI-D performance space.
List of the following materials will be included with the Downloaded Backup:
MInSC: A VLSI Architecture for Myocardial Infarction Stages Classifier for Wearable Healthcare Applications
Base Paper Abstract:
Myocardial Infarction (MI) is a critical heart abnormality causing millions of fatalities worldwide every year. MI progress in three stages based on its severity causing several changes in an Electrocardiogram (ECG) signal. It is very critical to capture these variations, which requires continuous monitoring of the ECG signal of the patient. Therefore, it becomes imperative to develop a low power VLSI architecture to address the prognosis of MI. In this brief, for the first time, an area and power efficient design of a five stage classifier is proposed, which detects the progression of various stages of MI using ECG beats in real time. The proposed architecture has an area and total power utilization of 1.38mm2 and 5.12µW, respectively at SCL 180nm Bulk CMOS technology. The low power and area requirements and multiclass classification capability of the proposed design make it suitable to be used in wearable devices.
List of the following materials will be included with the Downloaded Backup:
Multiloop Control for Fast Transient DC–DC Converter
Abstract:
A novel ac coupled feedback (ACCF) is proposed to alternatively realize fast transient response while inherently controlling the start-up in-rush current of a dc–dc switching converter. The proposed ACCF is modified from a conventional capacitor multiplier and connected between the outputs of the converter and the transconductance. With this supplemental feedback, the transient response has been significantly improved due to the gain-boosting effect around the compensator’s midband. Moreover, the ACCF circuit assists to manage the ramping speed of the output voltage during power-up, thereby eliminating the bulky soft-start circuit. The new controller is very simple to implement and occupies a tiny footprint on-chip. A buck converter with the proposed scheme has been fabricated using the 0.18-µm standard CMOS process with an active silicon area of 0.573 mm2. Measurement results show that the output voltage rises linearly for a soft-start period of 1.05 ms according to the designed slope. Excellent load transient responses are achieved under different load current steps; the output voltage overshoot/undershoot of 60 mV settles down within 10 µs for a load variation from 50 µA to 1 A in 1 µs. Moreover, the proposed converter maintains both excellent load and line regulations of 0.018 mV/mA and 0.0056 mV/mV, respectively.
List of the following materials will be included with the Downloaded Backup:
Multiplier-free Implementation of Galois Field Fourier Transform on a FPGA
Abstract:
A novel approach to implementing Galois Field Fourier Transform (GFT) is proposed that completely eliminates the need for any finite field multipliers by transforming the symbols from a vector representation to a power representation. The proposed method is suitable for implementing GFTs of prime and nonprime lengths on modern FPGAs that have a large amount of on-chip distributed embedded memory. For GFT of length 255 that is widely used in many applications, the proposed memory based implementation exhibits 25% improvement in latency, 27% improvement in throughput, and 56% reduction in power consumption compared to a finite field multiplier based implementation.
List of the following materials will be included with the Downloaded Backup:
New Majority Gate Based Parallel BCD Adder Designs for Quantum-dot Cellular Automata
Abstract:
In this paper, we first theoretically re-defined output decimal carry in terms of majority gates and proposed a carry look ahead structure for calculating all the intermediate output carries. We have used this method for designing the multi-digit decimal adders. Theoretically, our best n-digit decimal adder design reduces the delay and area-delay product (ADP) by 50% compared with previous designs. We have implemented our designs using QCA Designer tool. The proposed QCA Designer based 8-digit PBA-BCD adder achieves over 38% less delay compared with the best existing designs.
List of the following materials will be included with the Downloaded Backup:
Novel Block-Formulation and Area-Delay-Efficient Reconfigurable Interpolation Filter Architecture for Multi-Standard SDR Applications
Abstract: The input-matrix and the coefficient-matrix resizes when changes. An analysis of interpolation filter computation for different up-sampling factors is made in this paper to identify redundant computations and removed those by reusing partial results. Reuse of partial results eliminates the necessity of matrix resizing in interpolation filter computation. A novel block-formulation is presented to share the partial results for parallel computation of filter outputs of different up-sampling factors. Using the proposed block formulation, to increase the number of tab to 16 and to get the accuracy and reduce the delay. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
One-Sided Schmitt-Trigger-Based 9T SRAM Cell for Near-Threshold Operation
Abstract:
This paper presents a one-sided Schmitt-trigger based 9T static random access memory cell with low energy consumption and high read stability, write ability, and hold stability yields in a bit-interleaving structure without write-back scheme. The proposed Schmitt-trigger-based 9T static random access memory cell obtains a high read stability yield by using a one-sided Schmitt-trigger inverter with a single bit-line structure. In addition, the write ability yield is improved by applying selective power gating and a Schmitt-trigger inverter write assist technique that controls the trip voltage of the Schmitt-trigger inverter. The proposed Schmitt-trigger-based 9T static random access memory cell has 0.79, 0.77, and 0.79 times the area, and consumes 0.31, 0.68, and 0.90 times the energy of Chang’s 10T, the Schmitt-trigger-based 10T, and MH’s 9T static random access memory cells, respectively, based on 22-nm Fin FET technology.
List of the following materials will be included with the Downloaded Backup:
Optimized Dual Accumulator based RISC Architecture with Advanced Memory and Peripheral Operations
Proposed Abstract:
This paper presents an optimized Reduced Instruction Set Computer (RISC) architecture that leverages a dual accumulator design to enhance computational efficiency and performance. The architecture is scheduled to support advanced memory management and peripheral operations, addressing the growing need for high-speed data processing in embedded systems. The dual accumulator approach allows for parallel execution of arithmetic operations, reducing the number of instruction cycles and improving overall throughput. The architecture is designed with a focus on optimizing area, delay, and power consumption, making it suitable for resource-constrained environments. The proposed design is implemented using Verilog HDL and synthesized on the Xilinx Vivado platform targeting the Zynq FPGA. The architecture’s performance is verified through extensive simulation in Modelsim, and a comparative analysis is conducted to evaluate the improvements in key parameters such as area utilization, processing delay, and power efficiency. The results demonstrate that the optimized dual accumulator-based RISC architecture significantly outperforms traditional single accumulator designs, making it an ideal solution for modern embedded applications that require both high performance and low power consumption.
List of the following materials will be included with the Downloaded Backup:
Optimizing Ternary Multiplier Design with Fast Ternary Adder
Base Paper Abstract:
Existing ternary multiplier designs are difficult to use in ternary systems. Thus, ternary Wallace tree multipliers that reduce the number of transistors by using 4-input ternary adders are proposed to improve the performance of existing ternary multipliers. A ternary carry-select adder is also proposed to reduce the carry propagation delay, used as a carry-chain adder of the Wallace tree. The proposed multipliers are designed with a custom ternary standard cell library synthesized by multi-threshold complementary metal-oxide-semiconductor (CMOS) with a 28 nm process. Power and delay are verified via HSPICE simulation. The proposed 36 × 36 ternary multiplier shows 79.3% power-delay product improvement over the previous ternary multiplier. The proposed 40 × 40 ternary multiplier shows a power-delay product comparable with that of the 64 × 64 binary multiplier synthesized using Synopsys Design Compiler.
List of the following materials will be included with the Downloaded Backup:
OTA-Based Logarithmic Circuit for Arbitrary Input Signal and Its Application
In this paper, a new design procedure has been proposed for realization of logarithmic function via three phases: 1) differentiation; 2) division; and 3) integration for any arbitrary analog signal. All the basic building blocks, i.e., differentiator, divider, and integrator, are realized by operational transconductance amplifier, a current mode device. Realization of exponential, power law and hyperbolic function as the design examples claims that the proposed synthesis procedure has the potential to design a log-based nonlinear system in a systematic and hierarchical manner. The proposed architecture of this paper area and power consumption analysis using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Parallel Pipelined Architecture and Algorithm for Matrix Transposition Using Registers
Base Paper Abstract:
In this brief, we present a new algorithm and architecture for continuous-flow matrix transposition using registers. The algorithm supports P-parallel matrix transposition. The hardware architecture reaches the theoretical minimums in terms of latency and memory. It is composed of a group of identical cascaded basic swap circuits, whose stages are determined by the corresponding algorithm, and can be controlled via a set of counters. Compared with the state-of-the-art architecture, the proposed architecture supports matrices whose rows and columns are integer multiples of P. Here P can be arbitrary, including but not limited to power-of-two integers. Moreover, our results provide additional insight into continuous-flow non-square matrix transposition.
List of the following materials will be included with the Downloaded Backup:
Power Efficient Approximate Divider Architecture for Error Resilient Applications
Base Paper Abstract:
Approximate computing is an emerging paradigm in error-tolerant applications that leads to power-efficient designs without significant loss in quality. The divider in these applications have complex hardware and more latency among the computational blocks resulting in power consumption. Hence approximating the division module would lead to designs with vastly improved power efficiency. A new approximate subtractor (AxSUB) is proposed in this paper with the intent to reduce the hardware complexity while achieving accuracy within permissible limits. The proposed AxSUB and existing approximate subtractor units are used in the restoring array division (RAD) architecture to prove the efficacy of the AxSUB. Comprehensive error and synthesis analysis are performed on RAD architectures implemented using AxSUB, and existing methods. Our proposed design achieved a 21% decrease in area and a 28% decrease in power consumption compared to the exact design. The proposed and existing RAD architectures is implemented on change detection applications to validate the quality-effort tradeoff.
List of the following materials will be included with the Downloaded Backup:
Power Efficient Tiny Yolo CNN Using Reduced Hardware Resources Based on Booth Multiplier and WALLACE Tree Adders
Base Paper Abstract:
Convolutional Neural Network (CNN) has attained high accuracy and it has been widely employed in image recognition tasks. In recent times, deep learning-based modern applications are evolving and it poses a challenge in research and development of hardware implementation. Therefore, hardware optimization for efficient accelerator design of CNN remains a challenging task. A key component of the accelerator design is a processing element (PE) that implements the convolution operation. To reduce the amount of hardware resources and power consumption, this article provides a new processing element design as an alternate solution for hardware implementation. Modified BOOTH encoding (MBE) multiplier and WALLACE tree-based adders are proposed to replace bulky MAC units and typical adder tree respectively. The proposed CNN accelerator design is tested on Zynq-706 FPGA board which achieves a throughput of 87.03 GOP/s for Tiny-YOLO-v2 architecture. The proposed design allows to reduce hardware costs by 24.5% achieving a power efficiency of 61.64 GOP/s/W that outperforms the previous designs.
List of the following materials will be included with the Downloaded Backup:
Probability-Driven Evaluation of Lower-Part Approximation Adders
Abstract:
Parallel prefix adder topologies suffer from carry chains forming critical paths, limiting the performance and therefore the efficiency. We study approximation methods that offload the lower-part of calculation to an approximate unit and shorten the carry chain. We derive their accuracy models using probability theory. These models can replace Monte Carlo simulations. Furthermore, they can reveal better accuracy trade-offs without going through the RTL design, synthesis, and simulation of each unit and approximation level individually. Thus, they can eliminate the required design and simulation time and effort. After analyzing area-wise comparisons at varying number of approximated bits, we show that choosing a design that outperforms the others probabilistically also outperforms them in terms of accuracy, power, and performance trade-offs.
List of the following materials will be included with the Downloaded Backup:
Radiation-Hardened 0.3–0.9-V Voltage-Scalable 14T SRAM and Peripheral Circuit in 28-nm Technology for Space Applications
Abstract:
Conventional radiation-hardened cells of static random access memory (SRAM) are not robust enough in 28 nm technology, due to partial immunity of single-event upset (SEU) effect (Quatrobased cells) or insufficient critical charges in sensitive nodes (conventional stacked cells). The reduction of read noise margin (RNM) at the low supply voltage (VDD) confines these cells from low VDD applications. We propose a novel interleaving stacked-14T (ILS-14T) cell which prevents voltage transient from propagating to other redundancies. The ILS-14T cell can be resilient to both 0–1 and 1–0 upsets by injecting 12 mA in sensitive nodes. The critical charges of the ILS-14T cell are substantially larger than most other hardened cells at VDD from 0.3 to 0.9 V. The RNM of the ILS-14T cell is two times of most Quatro-based cells at 0.3 V VDD and larger than most cells at 0.6 and 0.9 V VDD. The area of occupation is 334% of the conventional 6T cell, which equals other 14T cells. The static–dynamic decoder array with 20%–40% area penalty and 116%–132% delay of rising edge, when compared with the conventional one, reduces the read failure rate by preventing single event transients (SETs) from propagating to unexpected word lines (WLs).
List of the following materials will be included with the Downloaded Backup:
Radiation-Hardened 14T SRAM Bit cell With Speed and Power Optimized for Space Application
Abstract:
In this paper, a novel radiation-hardened 14-transistor SRAM bit cell with speed and power optimized [radiation-hardened with speed and power optimized (RSP)-14T] for space application is proposed. By circuit- and layout-level optimization design in a 65-nm CMOS technology, the 3-D TCAD mixed-mode simulation results show that the novel structure is provided with increased resilience to single-event upset as well as single-event–multiple-node upsets due to the charge sharing among OFF-transistors. Moreover, the HSPICE simulation results show that the write speed and power consumption of the proposed RSP-14T are improved by ∼65% and ∼50%, respectively, compared with those of the radiation hardened design (RHD)-12T memory cell.
List of the following materials will be included with the Downloaded Backup:
RandShift: An Energy-Efficient Fault Tolerant Method in Secure Nonvolatile Main Memory
Abstract:
In this article, we present a simple, yet energy- and area-efficient method for tolerating the stuck-at faults caused by an endurance issue in secure-resistive main memories. In the proposed method, by employing the random characteristics of the encrypted data encoded by the Advanced Encryption Standard (AES) as well as a rotational shift operation, a large number of memory locations with stuck-at faults could be employed for correctly storing the data. Due to the simple hardware implementation of the proposed method, its energy consumption is considerably smaller than that of other recently proposed methods. The technique may be employed along with other error correction methods, including the error correction code (ECC) and the error correction pointer (ECP). To assess the efficacy of the proposed method, it is implemented in a phase-change memory (PCM)- based main memory system and compared with three error tolerating methods. The results reveal that for a stuck-at fault occurrence rate of 10−2 and with the uncorrected bit error rate of 2 × 10−3, the proposed method achieves 82% energy reduction compared to the state-of-the-art method. More generally, using a simulation analysis technique, we show that the fault coverage of the proposed method is similar to that of the state-of-the-art method.
List of the following materials will be included with the Downloaded Backup:
ReAdapt: A Reconfigurable Datapath for Runtime Energy-Quality Scalable Adaptive Filters
Base Paper Abstract:
This paper proposes ReAdapt–a reconfigurable datapath architecture for scaling the energy-quality trade-off of adaptive filtering at runtime. The ReAdapt can dynamically select four adaptive filtering algorithms for gradating complexity levels during runtime by reconfiguring the processing flow in its datapath and by blocking the switching activity (e.g., reducing the CMOS dynamic power) of unused modules with data-gating. The ReAdapt proposal can scale the energy-quality trade-off by choosing the following four different levels of filter algorithms complexity: 1) least mean square (LMS); 2) partial update normalized LMS (PU-NLMS); 3) set-membership normalized LMS (SM-NLMS); 4) normalized LMS (NLMS). The ReAdapt architecture reuses common modules of each adaptive filter, resulting in a compact VLSI hardware implementation. The ReAdapt architecture operation is implemented in a case-study for interference mitigation for electroencephalogram (EEG) signal processing. The hardware synthesis results show an increase of 6.80 times in throughput and at least a reduction of 2.84 times in energy per operation compared with the state-of-the-art adaptive filters. This paper also investigates the benefits of dynamically reconfiguring the four ReAdapt operating modes at runtime for different levels of signal-to-noise ratio (SNR) for the processed signals. We also demonstrate that dynamically reconfiguring the ReAdapt operating modes during runtime results in an optimal energy-quality trade-off which is advantageous over the conventional single static mode.
List of the following materials will be included with the Downloaded Backup:
Reconfigurable Architecture for Real-time Decoding of Canonical Huffman Codes
Base Paper Abstract:
Data compression is an important algorithm which has found its use in modern day algorithms such as Convolutional Neural Networks (CNNs). Reconfigurable platforms (like FPGAs) have strong capabilities to implement time complex tasks like CNNs, however, these algorithms present a big challenge due to high resource demand. Data compression is one of the most utilized techniques to reduce memory utilization in FPGAs. The weights of CNN architecture are usually encoded to store in FPGA. In this paper, we propose design of an efficient decoder based on Canonical Huffman that can be utilized for the efficient decompression of weights in CNN. The proposed design makes use of Hash functions to effectively decode the weights eliminating the need for searching dictionary. The proposed design decodes a single weight in a single clock cycle. Our proposed design has a maximum frequency of 408.97MHz utilizing 1% of system LUTs when tested for Aritix 7 platform.
List of the following materials will be included with the Downloaded Backup:
Reconfigurable Digital Delta-Sigma Modulation Transmitter Architecture for Concurrent Multi-Band Transmission
Abstract:
This paper presents a reconfigurable delta-sigma modulation (DSM) architecture for concurrent multi-band transmission. The reconfigurability in terms of carrier spacing and the number of simultaneous carrier transmission is useful for applications such as carrier aggregation in 5G. This paper uses 4th order reconfigurable multi-band DSM (RMB-DSM) such that the zeros of the noise transfer function can be reconfigured to fall at multiple frequencies, where the carriers are being aggregated. The quantization noise between the transmission bands is a critical issue in the case of multi-band transmission. Therefore, a multi-band additional noise shaping (ANS) function is also introduced, which generates notches around each carrier and reduces the noise level between the multiple pass-bands. The proposed scheme has been validated in simulation, as well as in experiment for aggregating up to four 15 MHz long term evolution (LTE) signals with an overall aggregated bandwidth of 60 MHz. Measurement results show a 10-25% improvement in coding efficiency and 15-35 dB improvement in noise level near the operating frequency band using the proposed multiband augmented noise shaping technique, as compared to the standard DSM. The corresponding improvement of 8% in the overall efficiency is observed by using the proposed multi-band augmented noise shaping technique.
List of the following materials will be included with the Downloaded Backup:
Recurrent Neural Networks With Column-Wise Matrix–Vector Multiplication on FPGAs
Abstract:
This article presents a reconfigurable accelerator for Recurrent Neural networks with fine-grained Column Wise matrix–vector multiplication (RENOWN). We propose a novel latency-hiding architecture for recurrent neural network (RNN) acceleration using column-wise matrix–vector multiplication (MVM) instead of the state-of-the-art row-wise operation. This hardware (HW) architecture can eliminate data dependencies to improve the throughput of RNN inference systems. Besides, we introduce a configurable checkerboard tiling strategy which allows large weight matrices, while incorporating various configurations of element-based parallelism (EP) and vector-based parallelism (VP). These optimizations improve the exploitation of parallelism to increase HW utilization and enhance system throughput. Evaluation results show that our design can achieve over 29.6 tera operations per second (TOPS) which would be among the highest for field-programmable gate array (FPGA)-based RNN designs. Compared to state-of-the-art accelerators on FPGAs, our design achieves 3.7–14.8 times better performance and has the highest HW utilization.
List of the following materials will be included with the Downloaded Backup:
Reliable CRC Based Error Detection Constructions for Finite Field Multipliers With Applications in Cryptography
Abstract:
Finite-field multiplication has received prominent attention in the literature with applications in cryptography and error-detecting codes. For many cryptographic algorithms, this arithmetic operation is a complex, costly, and time-consuming task that may require millions of gates. In this work, we propose efficient hardware architectures based on cyclic redundancy check (CRC) as error-detection schemes for postquantum cryptography (PQC) with case studies for the Luov cryptographic algorithm. Luov was submitted for the National Institute of Standards and Technology (NIST) PQC standardization competition and was advanced to the second round. The CRC polynomials selected are in-line with the required error-detection capabilities and with the field sizes as well. We have developed verification codes through which software implementations of the proposed schemes are performed to verify the derivations of the formulations. Additionally, hardware implementations of the original multipliers with the proposed error-detection schemes are performed over a Xilinx field-programmable gate array (FPGA), verifying that the proposed schemes achieve high error coverage with acceptable overhead.
List of the following materials will be included with the Downloaded Backup:
ReLOPE: Resistive RAM-Based Linear First-Order Partial Differential Equation Solver
Abstract:
Data movement between memory and processing units poses an energy barrier to Von-Neumann-based architectures. In-memory computing (IMC) eliminates this barrier. RRAM-based IMC has been explored for data-intensive applications, such as artificial neural networks and matrix-vector multiplications that are considered as “soft” tasks where performance is a more important factor than accuracy. In “hard” tasks such as partial differential equations (PDEs), accuracy is a determining factor. In this brief, we propose ReLOPE, a fully RRAM crossbar-based IMC to solve PDEs using the Runge–Kutta numerical method with 97% accuracy. ReLOPE expands the operating range of solution by exploiting shifters to shift input data and output data. ReLOPE range of operation and accuracy can be expanded by using fine-grained step sizes by programming other RRAMs on the BL. Compared to software-based PDE solvers, ReLOPE gains 31.4× energy reduction at only 3% accuracy loss.
List of the following materials will be included with the Downloaded Backup:
Resource and Energy Efficient Implementation of ECG Classifier using Binarized CNN for Edge AI Devices
Base Paper Abstract:
Wearable Artificial Intelligence-of-Things (AIoT) devices demand smart gadgets that are both resource and energy-efficient. In this paper, we explore efficient implementation of binary convolutional neural network employing function merging and block reuse techniques. The hardware implemented in field programmable gate array (FPGA) platform can classify ventricular beat in electrocardiogram achieving accuracy of 97.5%, sensitivity of 85.7%, specificity of 99.0%, precision of 92.3%, and F1-score of 88.9% while consuming only 10.5-µW of dynamic power dissipation.
List of the following materials will be included with the Downloaded Backup:
Reverse Converter Design via Parallel-Prefix Adders: Novel Components, Methodology, and Implementations
Abstract: The implementation of residue number system reverse converters based on well-known regular and modular parallel prefix adders is analyzed. The VLSI implementation results show a significant delay reduction and area × time2 improvements, all this at the cost of higher power consumption, which is the main reason preventing the use of parallel-prefix adders to achieve high-speed reverse converters in nowadays systems. Hence, to solve the high power consumption problem, novel specific hybrid parallel-prefix-based adder components those provide better tradeoff between delay and power consumption. The power, area and delay of the proposed system are analysis using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Scalable JTAG-Based 32-Bit Memory Test Architecture with MATS+ and MATS++/March-C Fault Detection
Proposed Abstract:
Embedded memories are increasingly used in advanced System-on-Chip (SoC) designs for applications such as networking, automotive control, and medical imaging, where reliability and performance are critical. Ensuring fault-free operation of these memories is essential, yet memory testing remains a major challenge. Conventional MBIST architectures, while effective, often introduce significant silicon overhead, add design complexity, and lack flexibility for post-fabrication updates. In addition, existing memory test algorithms have their own drawbacks: March-C is widely applied and provides high fault coverage, but it requires long test times due to bit-oriented operations and large numbers of read–write cycles; MATS+ is simple and efficient but suffers from lower coverage, particularly for coupling and complex dynamic faults; and MATS++ improves on MATS+ with better detection capability, yet it still trades off hardware cost and scalability when applied to larger 32-bit word-oriented memories. Furthermore, most existing implementations are optimized for small SRAMs and are not easily scalable to clustered embedded memories in SoCs, nor do they fully exploit standard boundary-scan infrastructure for low-cost testing. To address these problems, this work proposes a scalable JTAG-based 32-bit memory test architecture that reuses IEEE 1149.1 boundary-scan resources to apply and compare March-C, MATS+, and MATS++ algorithms in both single-bit and multi-bit test modes. The proposed framework minimizes additional hardware cost by integrating BIST control into boundary-scan registers, while enabling algorithm programmability and flexibility for different memory clusters. The novelty lies in providing a detailed performance comparison of these algorithms under a unified boundary-scan-based architecture, focusing on trade-offs between fault coverage, test time, and silicon overhead. The design is implemented in Verilog HDL and synthesized on an FPGA using Xilinx Vivado, where parameters such as area, power, and latency are evaluated to validate efficiency and practical applicability for SoC-level memory testing.
List of the following materials will be included with the Downloaded Backup:
Smart Intelligent and Adaptive Traffic Controller using FPGA
Proposed Abstract:
Traffic management is a critical aspect of modern urban infrastructure, and the ever-increasing volume of vehicles on the road demands innovative and adaptive solutions. This work presents a novel approach to traffic control using Field-Programmable Gate Arrays (FPGAs) as the core technology. The proposed system leverages the capabilities of FPGAs to create a Smart, Intelligent, and Adaptive Traffic Controller that can revolutionize urban traffic management. One of the key features of the proposed work is its adaptability. The system can dynamically adjust traffic signal timings and lane allocations in response to changing traffic patterns of 4-way road conditions with the help of sensor inputs. This methodology adaptability enhances road safety and minimizes traffic delays. The use of FPGA technology in the Traffic controller provides several advantages, including high computational performance, low power consumption, and the ability to reconfigure the system as traffic management needs evolve. Additionally, the system is highly scalable and can be deployed in various urban settings.
List of the following materials will be included with the Downloaded Backup:
Soft-Error-Aware Read-Stability-Enhanced Low-Power 12T SRAM With Multi-Node Upset Recoverability for Aerospace Applications
Abstract:
With the advancement of technology, the size of transistors and the distance between them are reducing rapidly. Therefore, the critical charge of sensitive nodes is reducing, making SRAM cells, used for aerospace applications, more vulnerable to soft-error. If a radiation particle strikes a sensitive node of the standard 6T SRAM cell, the stored data in the cell are flipped, causing a single-event upset (SEU). Therefore, in this paper, a Soft-Error-Aware Read-Stability-Enhanced Low Power 12T (SARP12T) SRAM cell is proposed to mitigate SEUs. To analyze the relative performance of SARP12T, it is compared with other recently published soft-error-aware SRAM cells, QUCCE12T, QUATRO12T, RHD12T, RHPD12T and RSP14T. All the sensitive nodes of SARP12T can regain their data even if the node values are flipped due to a radiation strike. Furthermore, SARP12T can recover from the effect of single event multi-node upsets (SEMNUs) induced at its storage node pair. Along with these advantages, the proposed cell exhibits the highest read stability, as the ‘0’-storing storage node, which is directly accessed by the bit line during read operation, can recover from any upset. Furthermore, SARP12T consumes the least hold power. SARP12T also exhibits higher write ability and shorter write delay than most of the comparison cells. All these improvements in the proposed cell are obtained by exhibiting only a slightly longer read delay and consuming slightly higher read and write energy.
List of the following materials will be included with the Downloaded Backup:
Soft-Error-Aware SRAM with Multinode Upset Tolerance for Aerospace Applications
Base Paper Abstract:
As technology scales down, the critical charge (QC) of vulnerable nodes decreases, making SRAM cells more susceptible to soft errors in the aerospace industry. This article proposes a Soft-Error-Aware 16T (S8P8N) SRAM cell for aerospace applications to address this issue. The properties of S8P8N are evaluated and compared with 6T, DICE, QUCCE12T, WEQUATRO, RHBD10T, RHBD12T, S4P8N, SEA14T, and SRRD12T. Simulation results indicate that all vulnerable nodes and key node pairs of the proposed cell can recover to their original states when affected by a soft error. Additionally, it can recover from key multinode upsets. The write speed of the proposed cell is found to be reduced by 20.3%, 50.1%, 74.1%, 63.7%, and 50.41% compared to 6T, DICE, QUCCE12T, WEQUATRO, and RHBD10T, respectively. The read speed of the proposed cell is found to be reduced by 56.6%, 52.2%, 62.5%, and 35.2% compared to 6T, SRRD12T, RHBD12T, and S4P8N, respectively. It also shows that the hold power of the proposed cell is found to be reduced by 14.1%, 13.8%, 17.7%, and 23.4% compared to DICE, WEQUATRO, RHBD10T, and RHBD12T. Furthermore, the read static noise margin (RSNM) of the proposed cell is found to be enhanced by 157%, 67%, and 32% compared to RHBD12T, SEA14T, and SRRD12T. All these improvements are achieved with a slight area penalty.
List of the following materials will be included with the Downloaded Backup:
Sparse FIR Filter Design via Partial 1-Norm Optimization
Abstract:
Electrocardiogram (ECG) is a form of cardiovascular measurement, for the diagnosis of different heart rate conditions. However, numerous noises usually harm the amplitude and time period of the signal from the ECG signal, at following a transition of the analog ECG signal from the sensor module into a digital format. The appropriate digital filter may be used to remove different forms of noise such as Baseline Wander, Power line interference, High frequency noise and Physiological Artifacts. The Digital FIR filter will have prospected to reduced the artifacts in the ECG signals. The signals taken from the MIT-BIH data base which contains the normal and abnormal waveforms. This Digital FIR filter can have more performance by using more TAP numbers such as multiplying, delaying and getting more effectiveness. This proposed work would implement a 1 norm minimization in the FIR filter with liner step method to minimize sparse complexity and reduce the mini-max approximation error for sparse maximization. Given these facts, several rules for selecting indicators of potential zero coefficients to be used in 1 standard optimization are adopted in the proposed algorithm. The efficacy of the proposed design algorithm was developed in Verilog HDL, simulated in Modelsim software and synthesized in Xilinx vertex 5 FPGA, and finally prove all the parameters in terms of area, delay and power.
List of the following materials will be included with the Downloaded Backup:
Static Delay Variations Modules For Ripple-Carry and Borrow Save Adders
Abstract:
This paper introduces two statistical delay variability models for certain hardware adder implementations, namely, the ripple-carry adder (RCA) and the borrow-save adder (BSA). The introduced models take into account correlated variation sources. Initially, we derive a first proposed model, namely, Type-I model, in the form of expressions for the computation of the exact Probability Density Functions (PDFS) of maximum output delays for Gaussian and non-Gaussian variation sources. Furthermore, we present closed formulas for the co-variances between output delays of the aforementioned adder architectures. The introduced derived co-variances are subsequently combined with Clark’s method to derive a second proposed model, Type-II model, which comprises approximations of the maximum delay PDF for an RCA and a BSA. Simulation results and the derived exact Type-I PDFs are found to perfectly agree, while the proposed Clark-based Type-II models present an error for standard deviation of maximum delay that increases as BSA word length increases. Both the introduced models and the simulations prove that BSAs achieve narrower delay distributions than RCAs, i.e., they significantly reduce delay variance. Consequently, BSAs are proven to be suitable for variation-tolerant applications by providing a timing safety margin, when compared to RCA architectures. The underlying analysis indicates that for the case of BSA and either intra-die delay variations only or both intra and inter-die delay variations, the Type-II models introduce non negligible errors, which are as much as 16% of the standard deviation of maximum delay for a 256-digit BSA, as the Type II Gaussian PDF approximations deviate significantly from the exact Type-I PDFs. However, for all RCA and BSA inter-die only variation cases, both types present satisfactory accuracy due to the Gaussian shape of exact PDF.
List of the following materials will be included with the Downloaded Backup:
The Mesochronous Dual-Clock FIFO Buffer
Abstract:
To increase system composability and facilitate timing closure, fully synchronous clocking is replaced by more relaxed clocking schemes, such as mesochronous clocking. Under this regime, the modules at the two ends of a mesochronous interface receive the same clock signal, thus operating under the same clock frequency, but the edges of the arriving clock signals may exhibit an unknown phase relationship. In such cases, clock synchronization is needed when sending data across modules. In this brief, we present a novel mesochronous dual-clock first-input– first-output (FIFO) buffer that can handle both clock synchronization and temporary data storage, by synchronizing data implicitly through the explicit synchronization of only the flow-control signals. The proposed design can operate correctly even when the transmitter and the receiver are separated by a long link whose delay cannot fit within the target operating frequency. In such scenarios, the proposed mesochronous FIFO can be extended to support multicycle link delays in a modular manner and with minimal modifications to the baseline architecture. When compared with the other state-of-the-art dual-clock mesochronous FIFO designs, the new architecture is demonstrated to yield a substantially lower cost implementation.
List of the following materials will be included with the Downloaded Backup:
To develop and Implement Low Power, High Speed VLSI for Processing Signals using Multi rate Techniques Low Power Divider Using Vedic Mathematics
Abstract:
Multirate technique is necessary for systems with different input and output sampling rates. Recent advances in mobile computing and communication applications demand low power and high speed VLSI DSP systems. In this paper to discuss the downsampling technique and its improvement, major drawbacks of present approaches possible to increase degeneracy. This Multirate design methodology is systematic and applicable to many problems. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
TOSAM: An Energy-Efficient Truncation- and Rounding-Based Scalable Approximate Multiplier
Abstract:
A scalable approximate multiplier, called truncation- and rounding-based scalable approximate multiplier (TOSAM) is presented, which reduces the number of partial products by truncating each of the input operands based on their leading one-bit position. In the proposed design, multiplication is performed by shift, add, and small fixed-width multiplication operations resulting in large improvements in the energy consumption and area occupation compared to those of the exact multiplier. To improve the total accuracy, input operands of the multiplication part are rounded to the nearest odd number. Because input operands are truncated based on their leading one-bit positions, the accuracy becomes weakly dependent on the width of the input operands and the multiplier becomes scalable. Higher improvements in design parameters (e.g., area and energy consumption) can be achieved as the input operand widths increase. To evaluate the efficiency of the proposed approximate multiplier, its design parameters are compared with those of an exact multiplier and some other recently proposed approximate multipliers. Results reveal that the proposed approximate multiplier with a mean absolute relative error in the range of 11%–0.3% improves delay, area, and energy consumption up to 41%, 90%, and 98%, respectively, compared to those of the exact multiplier. It also outperforms other approximate multipliers in terms of speed, area, and energy consumption. The proposed approximate multiplier has an almost Gaussian error distribution with a near-zero mean value. We exploit it in the structure of a JPEG encoder, sharpening, and classification applications. The results indicate that the quality degradation of the output is negligible. In addition, we suggest an accuracy configurable TOSAM where the energy consumption of the multiplication operation can be adjusted based on the minimum required accuracy.
List of the following materials will be included with the Downloaded Backup:
Toward the Multiple Constant Multiplication at Minimal Hardware Cost
Base Paper Abstract:
Multiple Constant Multiplication (MCM) over integers is a frequent operation arising in embedded systems that require highly optimized hardware. An efficient way is to replace costly generic multiplication by bit-shifts and additions, i. e. a multiplier less circuit. In this work, we improve the state of-the-art optimal approach for MCM, based on Integer Linear Programming (ILP). We introduce a new low-level hardware cost metric, which counts the number of one-bit adders and demonstrate that it is strongly correlated with the LUT count. This new model permitted us to consider intermediate truncations that permit to significantly save resources when a full output precision is not required. We incorporate the error propagation rules into our ILP model to guarantee a user-given error bound on the MCM results. The proposed ILP models for multiple flavors of MCM are implemented as an open-source tool and, combined with an automatic code generator, provide a complete coefficient-to-VHDL flow. We evaluate our models in extensive experiments, and propose an in-depth analysis of the impact that design metrics have on synthesized hardware.
List of the following materials will be included with the Downloaded Backup:
Towards Efficient Modular Adders based on Reversible Circuits
Abstract:
Reversible logic is a computing paradigm that has attracted significant attention in recent years due to its properties that lead to ultra-low power and reliable circuits. Reversible circuits are fundamental, for example, for quantum computing. Since addition is a fundamental operation, designing efficient adders is a cornerstone in the research of reversible circuits. Residue Number Systems (RNS) has been as a powerful tool to provide parallel and fault-tolerant implementations of computations where additions and multiplications are dominant. In this paper, for the first time in the literature, we propose the combination of RNS and reversible logic. The parallelism of RNS is leveraged to increase the performance of reversible computational circuits. Being the most fundamental part in any RNS, in this work we propose the implementation of modular adders, namely modulo 2n-1 adders, using reversible logic. Analysis and comparison with traditional logic show that modulo adders can be designed using reversible gates with minimum overhead in comparison to regular reversible adders.
List of the following materials will be included with the Downloaded Backup:
Two Efficient Approximate Unsigned Multipliers by Developing New Configuration for Approximate 4:2 Compressors
Base Paper Abstract:
Approximate computing is a promising approach for reducing power consumption and design complexity in applications that accuracy is not a crucial factor. Approximate multipliers are commonly used in error-tolerant applications. This paper presents three approximate 4:2 compressors and two approximate multiplier designs, aiming at reducing the area and power consumption, while maintaining acceptable accuracy. The paper seeks to develop approximate compressors that align positive and negative approximations for input patterns that have the same probability. Additionally, the proposed compressors are utilized to construct approximate multipliers for different columns of partial products based on the input probabilities of the two compressors in adjacent columns. The proposed approximate multipliers are synthesized using the 28nm technology. Compared to the exact multiplier, the first proposed multiplier improves power × delay and area × power by 91% and 86%, respectively, while the second proposed multiplier improves the two parameters by 90% and 84%, respectively. The performance of the proposed approximate methods was assessed and compared with the existing methods for image multiplication, sharpening, smoothing and edge detection. Also, the performance of the proposed multipliers in the hardware implementation of the neural network was investigated, and the simulation results indicate that the proposed multipliers have appropriate accuracy in these applications.
List of the following materials will be included with the Downloaded Backup:
Two-Stage OTA With All Subthreshold MOSFETs and Optimum GBW to DC-Current Ratio
Base Paper Abstract:
An approach for the design of two-stage class AB OTAs with sub-1µA current consumption is proposed and demonstrated. The approach employs MOS transistors operating in subthreshold and allows maximum gain-bandwidth product (GBW) to be achieved for a given DC current budget, by setting optimum distribution of DC currents in the two amplifier stages. Following this strategy, a class AB OTA was designed in a standard 0.5-µm CMOS technology supplied from 1.6-V and experimentally tested. Measured GBW was 307 kHz with 980-nA DC current consumption while driving an output capacitance of 40 pF with an average slew rate of 96 V/ms.
List of the following materials will be included with the Downloaded Backup:
Ultra Lightweight Cryptography: Exploring the Application and Optimization of the PRESENT Cipher
Proposed Abstract:
The PRESENT cipher, an ultra-lightweight block cipher, has been designed specifically for environments where resource constraints are a critical factor, such as RFID tags, sensor networks, and various IoT devices. Its compact design, featuring a 64-bit block size, 80-bit key, and 31 rounds, makes it particularly suitable for applications requiring minimal hardware resources, low power consumption, and moderate security. Unlike more robust ciphers like AES, which demand significant computational and memory resources, PRESENT strikes an optimal balance between efficiency and security for constrained devices. This paper explores the practical applications of the PRESENT cipher in secure communication protocols, device authentication, and data encryption in low-power systems. By synthesizing 16-bit, 32-bit, and 64-bit implementations on a Xilinx Virtex-5 FPGA, we demonstrate the cipher’s adaptability across a range of use cases, analyzing key performance metrics such as area, delay, and power consumption. Our findings indicate that PRESENT is highly effective in scenarios where traditional cryptographic solutions are too resource-intensive, offering a viable alternative for securing data in pervasive computing environments. PRESENT’s applications extend to securing communication in embedded systems, protecting sensitive information in contactless payment systems, and enabling secure data transmission in wireless sensor networks. The cipher’s lightweight design ensures that it can be implemented in devices with limited processing capabilities, making it an ideal choice for modern IoT applications. However, the trade-off between security and efficiency must be carefully considered. While PRESENT is suitable for applications with moderate security requirements, it may not provide the level of protection needed for high-security environments.
List of the following materials will be included with the Downloaded Backup:
Variable-Precision Approximate Floating-Point Multiplier for Efficient Deep Learning Computation
Base Paper Abstract:
In this brief, a variable-precision approximate floating-point multiplier is proposed for energy efficient deep learning computation. The proposed architecture supports approximate multiplication with BFloat16 format. As the input and output activations of deep learning models usually follow normal distribution, inspired by the posit format, for numbers with different values, different precisions can be applied to represent them. In the proposed architecture, posit encoding is used to change the level of approximation, and the precision of the computation is controlled by the value of product exponent. For large exponent, smaller precision multiplication is applied to mantissa and for small exponent, higher precision computation is applied. Truncation is used as approximate method in the proposed design while the number of bit positions to be truncated is controlled by the values of the product exponent. The proposed design can achieve 19% area reduction and 42% power reduction compared to the normal BFloat16 multiplier. When applying the proposed multiplier in deep learning computation, almost the same accuracy as that of normal BFloat16 multiplier can be achieved.
List of the following materials will be included with the Downloaded Backup:
Vital-Sign Processing Receiver With Clutter Elimination Using Servo Feedback Loop for UWB Pulse Radar System
Abstract:
This brief presents a vital-sign processing circuit for simultaneous dc/near-dc elimination and out-of-band interference rejection without any digital signal processing or algorithm assistance for the ultra wideband (UWB) pulse-based radar system. An intrinsic self balanced MOS diode (SBMD) was proposed as a stable and balanced pseudo resistor applied under a servo feedback loop in a vital-sign receiver of the sensing radar to perform as a high-pass filter (HPF) with an ultralow corner frequency lower than 0.5 Hz for removing undesired clutters of the reflected signals and input dc-offset voltages from innate circuit offsets. A third-order switched-capacitor (SC) Chebyshev low-pass filter (LPF) with leap-frog topology as the subsequent stage was adopted to suppress the out-band noises, thereby establishing an integrated vital-sign processing circuit with band pass frequency response and incorporating it into a radar module to verify its viability.
List of the following materials will be included with the Downloaded Backup:
VLSI Design of SVM-Based Seizure Detection System With On-Chip Learning Capability
Abstract:
Portable automatic seizure detection system is very convenient for epilepsy patients to carry. In order to make the system on-chip trainable with high efficiency and attain high detection accuracy, this paper presents a very large scale integration (VLSI) design based on the nonlinear support vector machine (SVM). The proposed design mainly consists of a feature extraction (FE) module and an SVM module. The FE module performs the three level Daubechies discrete wavelet transform to fit the physiological bands of the electroencephalogram (EEG) signal and extracts the time–frequency domain features reflecting the non stationary signal properties. The SVM module integrates the modified sequential minimal optimization algorithm with the table-driven-based Gaussian kernel to enable efficient on-chip learning. The presented design is verified on an Altera Cyclone II field-programmable gate array and tested using the two publicly available EEG datasets. Experiment results show that the designed VLSI system improves the detection accuracy and training efficiency.
List of the following materials will be included with the Downloaded Backup:
World’s Fastest FFT Architectures: Breaking the Barrier of 100 GS/s
Abstract:
This paper presents the fastest fast Fourier transform (FFT) hardware architectures so far. The architectures are based on a fully parallel implementation of the FFT algorithm. In order to obtain the highest throughput while keeping the resource utilization low, we base our design on making use of advanced shift-and-add techniques to implement the rotators and on selecting the most suitable FFT algorithms for these architectures. Apart from high throughput and resource efficiency, we also guarantee high accuracy in the proposed architectures. For the implementation, we have developed an automatic tool that generates the architectures as a function of the FFT size, input word length and accuracy of the rotations. We provide experimental results covering various FFT sizes, FFT algorithms, and field-programmable gate array boards. These results show that it is possible to break the barrier of 100 GS/s for FFT calculation.
List of the following materials will be included with the Downloaded Backup:Provide Wordlwide Online Support
We can provide Online Support Wordlwide, with proper execution, explanation and additionally provide explanation video file for execution and explanations.
24/7 Support Center
NXFEE, will Provide on 24x7 Online Support, You can call or text at +91 9789443203, or email us nxfee.innovation@gmail.com
Terms & Conditions:
Customer are advice to watch the project video file output, and before the payment to test the requirement, correction will be applicable.
After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
Online support will not be given more than 3 times.
On first time explanation we can provide completely with video file support, other 2 we can provide doubt clarifications only.
If any Issue on Software license / System Error we can support and rectify that within end of day.
Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
After payment, to must send the payment receipt to our email id.
Powered by NXFEE INNOVATION, Pondicherry.
Call us today at : +91 9789443203 or Email us at nxfee.innovation@gmail.com
NXFEE Development & Services

Product Categories
- 2014 (11)
- 2015 (39)
- 2016 (30)
- 2017 (16)
- 2018 (17)
- 2019 (42)
- 2020 (29)
- 2021 (17)
- 2022 (23)
- Accessories (43)
- Area Efficient (116)
- High speed VLSI Design (56)
- IEEE (15)
- Image Processing (40)
- Low power VLSI Design (97)
- NOC VLSI Design (2)
- VLSI (249)
- VLSI 2023 (21)
- VLSI 2024 (18)
- VLSI 2025 (30)
- VLSI 2026 (3)
- VLSI Application / Interface and Mini Projects (31)
- VLSI_2023 (15)
Filter by price
Product Status
Sort by producents

Copyright © 2026 Nxfee Innovation.