IEEE Transactions on VLSI 2015
Following Novelty based Research Projects not yet Published in Any Journal
Customization Available for Journal Publications
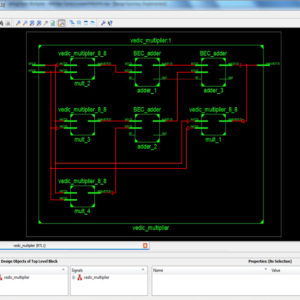
A Comparative Analysis of Multiplier Topologies using Different Vedic Sutras
Abstract: The need of low area and high speed Multiplier is increasing as the need of high speed processors are needed. The multipliers used in Square and cube architecture have to be more efficient in area and also in speed. In this paper a multiplier is implemented based on Nikhilam sutra with binary excess unit. The ripple carry adder in the multiplier architecture increases the speed of addition of partial products. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup: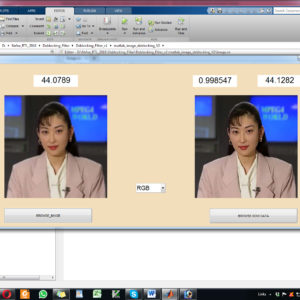
A Deblocking Filter Hardware Architecture for the High Efficiency Video Coding Standard
The new deblocking filter (DF) tool of the next generation High Efficiency Video Coding (HEVC) standard is one of the most time consuming algorithms in video decoding. In order to achieve real-time performance at low-power consumption, we developed a hardware accelerator for this filter. This paper proposes high throughput hardware architecture for HEVC deblocking filter employing hardware reuse to accelerate filtering decision units with a low area cost. Our architecture achieves either higher or equivalent throughput with 5X-6X lower area compared to state of-the-art deblocking filter architectures. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup: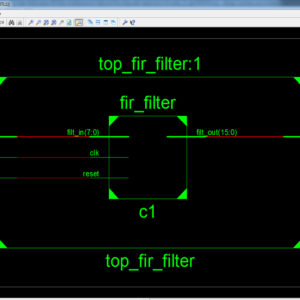
A High Performance FIR Filter Architecture for Fixed and Reconfigurable Applications
Abstract:
Transpose form finite-impulse response (FIR)filters are inherently pipelined and support multiple constant multiplications (MCM) technique that results in significant saving of computation. However, transpose form configuration does not directly support the block processing unlike direct form configuration. In this paper, we explore the possibility of realization of block FIR filter in transpose form configuration for area-delay efficient realization of large order FIR filters for both fixed and reconfigurable applications. Based on a detailed computational analysis of transpose form configuration of FIR filter, we have derived a flow graph for transpose form block FIR filter with optimized register complexity. A generalized block formulation is presented for transpose form FIR filter. We have derived a general multiplier-based architecture for the proposed transpose form block filter for reconfigurable applications. A low-complexity design using the MCM scheme is also presented for the block implementation of fixed FIR filters. The proposed structure involves significantly less area delay product (ADP) and less energy per sample (EPS) than the existing block implementation of direct-form structure for medium or large filter lengths, while for the short-length filters, the block implementation of direct-form FIR structure has less ADP and less EPS than the proposed structure. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup: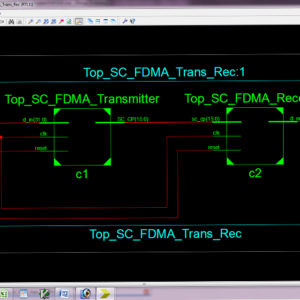
A High-Throughput VLSI Architecture for Hard and Soft SC-FDMA MIMO Detectors
Abstract:
A novel low-complexity multiple-input multiple-output (MIMO) detector tailored for single-carrier frequency division-multiple access (SC-FDMA) systems, suitable for efficient hardware implementations. The proposed detector starts with an initial estimate of the transmitted signal based on a minimum mean square error (MMSE) detector. Subsequently, it recognizes less reliable symbols for which more candidates in the constellation are browsed to improve the initial estimate. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup: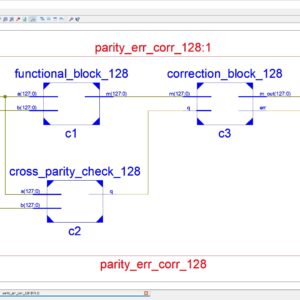
A Low-Complexity Multiple Error Correcting Architecture Using Novel Cross Parity Codes Over GF(2 m)
Abstract: This paper presents a modern low- complexity cross parity code, with a wide range of multiple bit error correction capability at a lower overhead, for improving the reliability. We have to use the two type of error correction technique for 128bit; first one is single bit error correction by using the hamming code. This hamming code is detects and then correct the single bit error correction. Another one is multiple bits error correction by using BCH (Bose–Choudhury– Hocquenghem). This one corrects the multiple bits error. Finally these are implemented and get the simulated result is compared to the previous architecture. The code are simulated and power, area, cost are taken using Xilinx 14.2 software.
List of the following materials will be included with the Downloaded Backup:
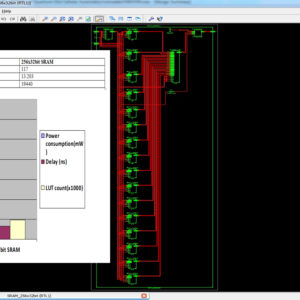
A Novel Quantum Dot Cellular Automata X bit × 32 bit SRAM
Application of quantum-dot cellular automata (QCA) technology as an alternative to CMOS technology on the nanoscale has a promising future; QCA is an interesting technology for building memory. The proposed design and simulation of a new memory cell structure based on QCA with a minimum delay, area, and complexity is presented to implement a static random access memory (SRAM). This paper presents the design and simulation of a 16-bit × 32-bit SRAM with a new structure in QCA. Since QCA is a pipeline, this SRAM has a high operating speed. The 16-bit × 32-bit SRAM has a new structure with a 32-bit width designed and implemented in QCA. It has the ability of a conventional logic SRAM that can provide read/write operations frequently with minimum delay. The 16-bit × 32-bit SRAM is generalized and an n × 16-bit × 32-bit SRAM is implemented in QCA. Novel 16-bit decoders and multiplexers (MUXs) in QCA are presented that have been designed with a minimum number of majority gates and cells. The new SRAM, decoders, and MUXs are designed, implemented, and simulated in QCA using a signal distribution network to avoid the coplanar problem of crossing wires. The QCA-based SRAM cell was compared with the SRAM cell based on CMOS. Results show that the proposed SRAM is more efficient in terms of area, complexity, clock frequency, latency, throughput, and power consumption.
List of the following materials will be included with the Downloaded Backup:
A Thermal Energy Harvesting Power Supply with an Internal Start up Circuit
A complete thermal energy harvesting power supply for implantable pacemakers is presented in this paper. The designed power supply includes an internal startup and does not need any external reference voltage. The startup circuit includes a prestart up charge pump (CP) and a startup boost converter. The prestart up CP consists of an ultralow-voltage oscillator followed by a high-efficiency modified Dickson. Forward body biasing is used to effectively reduce the MOS threshold voltages as well as the supply voltage in oscillator and CP. The steady-state circuit includes a high-efficiency boost converter that utilizes a modified maximum power point tracking scheme. The system is designed so that no failure occurs under overload conditions. Using this approach, a thermal energy harvesting power supply has been designed using 130-nm CMOS technology with low dropout regulator. Finally we are got the output of 2.5V in 10ms.
List of the following materials will be included with the Downloaded Backup:
A VLSI Architecture for Watermarking of Gray scale Images using Weighted Median Prediction
Abstract:
Watermarking the digital data is a familiar technique to authenticate and resolve the copyright issues of multimedia data. This paper proposes a new VLSI architecture for watermarking grayscale images using weighted median prediction operation, as this mechanism will have a minimum computation complexity. In this VLSI based data hiding process the secret digital signature is hidden in the host image and analyzed with the PSNR value and Payload capacity.
List of the following materials will be included with the Downloaded Backup:
Algorithm and Architecture for a Low Power Content Addressable Memory Based on Sparse Clustered Networks
Abstract: We propose a low-power content-addressable memory (CAM) employing a new algorithm for associativity between the input tag and the corresponding address of the output data of 128bit. The proposed architecture is based on a recently developed sparse clustered network using binary connections that on-average eliminates most of the parallel comparisons performed during a search. Therefore, the dynamic energy consumption of the proposed design is significantly lower compared with that of a conventional low-power CAM design. Given an input tag, the proposed architecture computes a few possibilities for the location of the matched tag and performs the comparisons on them to locate a single valid match. A design methodology based on the silicon area and power budgets, and performance requirements is discussed. The proposed architecture of this paper will be analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
An Efficient Constant Multiplier Architecture Based on Vertical-Horizontal Binary Common Sub-expression Elimination Algorithm for Reconfigurable FIR Filter Synthesis.
Abstract: This paper proposes efficient constant multiplier architecture based on vertical-horizontal binary common sub-expression elimination (VHBCSE) algorithm for designing a reconfigurable finite impulse response (FIR) filter whose coefficients can dynamically change in real time. To design an efficient reconfigurable FIR filter, according to the proposed VHBCSE algorithm, 2-bit binary common sub-expression elimination (BCSE) algorithm has been applied vertically across adjacent coefficients on the 2-D space of the coefficient matrix initially, followed by applying variable-bit BCSE algorithm horizontally within each coefficient. Faithfully rounded truncated multiple constant multiplication/accumulation (MCMAT) and multi-root binary partition graph (MBPG) respectively. Efficiency shown by the results of comparing the FPGA and ASIC implementations of the reconfigurable FIR filter designed using VHBCSE algorithm based constant multiplier establishes the suitability of the proposed algorithm for efficient fixed point reconfigurable FIR filter synthesis.
List of the following materials will be included with the Downloaded Backup:
ASIC design of UHF RFID reader digital baseband
This paper presents the ASIC design and implementation of digital baseband system for UHF RFID reader based on EPC Global C1G2 /ISO 18000-6c protocol. The digital baseband system consists of two parts :transmitter and receiver, which including encoding module, decoding module, channel filers, CRC check module, control module and a SPI module. It is described in verilog HDL in RTL level, with Design Complier for synthesizing, PT for static timing analyzing and Astro for physical design. The die is fabricated using IBM 130nm 8-layer-metal RF CMOS process successfully, which size is 3 mm x 3mm, the power consumption is around 6.7mW. It can be applied in the research of single-chip UHF RFID reader. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Block Interleaver Design for High Data Rate Wireless Networks
With increasing data rates in wireless communication, quality of service (QoS) has become a major issue. This is more with fading channels transmitting huge volumes of data. QoS is degraded by inter-symbol interference (ISI) and related errors. One of the simplest and convenient techniques to overcome such errors is interleaving, which is used efficiently in wireless applications. It has found applications for combating burst errors that creeps up in the channel during transmission. In this paper, an efficient model of a block interleaver using a hardware description language (Verilog) is proposed. The proposed technique reduces consumption of FPGA resources to a large extent, which implies low power consumption. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Byte-Reconfigurable LDPC Codec Design With Application to High-Performance ECC of NAND Flash Memory Systems
Abstract: In information theory, a low-density parity-check (LDPC) code is a linear error correcting code, a method of transmitting a message over a noisy transmission channel. An LDPC is constructed using a sparse bipartite graph. LDPC codes are capacity-approaching codes, which means that practical constructions exist that allow the noise threshold to be set very close (or even arbitrarily close on the BEC) to the theoretical maximum (the Shannon limit) for a symmetric memory-less channel. The noise threshold defines an upper bound for the channel noise, up to which the probability of lost information can be made as small as desired. Using iterative belief propagation techniques, LDPC codes can be decoded in time linear to their block length.
List of the following materials will be included with the Downloaded Backup:
Design and Analysis of Approximate Compressors for Multiplication
Inexact computing is particularly interesting for computer arithmetic designs. Implementation of 8X8 truncated multipliers using Very High Speed Integrated Circuit Hardware Description Language (VHDL). Truncated multipliers can be used in the image multiplication application. This multiplier is automatically truncating the output and reduces the power consumption and are comparing to other multipliers. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Design and Low-Complexity Implementation of Matrix–Vector Multiplier for Iterative Methods in Communication Systems
Abstract: Iterative methods are basic building blocks of communication systems and often represent a dominating part of the system, and therefore, they necessitate careful design and implementation for optimal performance. In this brief, we propose a novel field programmable gate arrays design of matrix–vector multiplier that can be used to efficiently implement widely adopted iterative methods. The proposed design exploits the sparse structure of the matrix as well as the fact that spreading code matrices have equal magnitude entries. Implementation details and timing analysis results are promising and are shown to satisfy most modern communication system requirements.
List of the following materials will be included with the Downloaded Backup:
Design of 4-bit Ripple carry adder and using 9T full adder
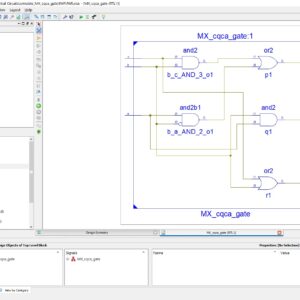
Design of Testable Reversible Sequential Circuits
Abstract: In this paper, we propose the design of two vectors testable sequential circuits based on conservative logic gates. The proposed sequential circuits based on conservative logic gates outperform the sequential circuits implemented in classical gates in terms of testability. Any sequential circuit based on conservative logic gates can be tested for classical unidirectional stuck-at faults using only two test vectors. The two test vectors are all 1s, and all 0s. The designs of two vectors testable latches, master-slave flip-flops and double edge triggered (DET) flip-flops are presented. The importance of the proposed work lies in the fact that it provides the design of reversible sequential circuits completely testable for any stuck-at fault by only two test vectors, thereby eliminating the need for any type of scan-path access to internal memory cells. The reversible design of the DET flip-flop is proposed for the first time in the literature. We also showed the application of the proposed approach toward 100% fault coverage for single missing/additional cell defect in the quantum dot cellular automata (QCA) layout of the Fredkin gate. We are also presenting a new conservative logic gate called multiplexer conservative QCA gate (MX-cqca) that is not reversible in nature but has similar properties as the Fredkin gate of working as 2:1 multiplexer. The proposed MX-cqca gate surpasses the Fredkin gate in terms of complexity (the number of majority voters), speed, and area.
List of the following materials will be included with the Downloaded Backup:
Dual Use of Power Lines for Design for Testability A CMOS Receiver Design
As the circuit complexity increases, the number of internal nodes increases proportionally, and individual internal nodes are less accessible due to the limited number of available I/O pins. To address the problem, we proposed power line communications (PLCs) at the IC level, specifically the dual use of power pins and power distribution networks for application/ observation of test data as well as delivery of power. A PLC receiver presented in this paper intends to demonstrate the proof of concept, specifically the transmission of data through power lines. The main design objective of the proposed PLC receiver is the robust operation under variations and droops of the supply voltage rather than high data speed. The PLC receiver is designed and fabricated in CMOS 0.18-µm technology under a supply voltage of 1.8V.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of Partially Parallel Encoder Architecture for Long Polar Code
Polar coding is an encoding/decoding scheme that provably achieves the capacity of the class of symmetric binary memory-less channels. Due to the channel achieving property, the polar code has become one of the most favourable error-correcting codes. As the polar code achieves the property asymptotically, however, it should be long enough to have a good error-correcting performance. Although previous fully parallel encoder is intuitive and easy to implement, it is not suitable for long polar codes because of the huge hardware complexity required. In the brief, we analyse the encoding process in the viewpoint of very large-scale integration implementation and propose a new efficient encoder architecture that is adequate for long polar codes and effect in alleviating the hardware complexity. As the proposed encoder allows high-throughput encoding with small hardware complexity, it can be systematically applied to the design of any polar code and to any level of parallelism. Finally shown the power, area, delay report with comparison of existing work.
List of the following materials will be included with the Downloaded Backup:

Fully Pipelined Low-Cost and High-Quality Color Demosaicking VLSI Design for Real-Time Video Applications
This system presents a fully pipelined color demosaicking design. To improve the quality of reconstructed images, a linear deviation compensation scheme was created to increase the correlation between the interpolated and neighboring pixels. Furthermore, immediately interpolated green color pixels are first to be used in hardware-oriented color demosaicking algorithms, which efficiently promoted the quality of the reconstructed image. A boundary detector and boundary mirror machine were added to improve the quality of pixels located in boundaries. In addition, a hardware sharing technique was used to reduce the hardware costs of three interpolators. Finally these are implemented and get the simulated result is compared to the previous architecture. The code are simulated and power, area, cost are taken using Xilinx 14.2 software and MATLAB. Compared with the previous low complexity designs, this work has the benefits in terms of low cost, low power consumption, and high performance.
List of the following materials will be included with the Downloaded Backup:
Fully Reused VLSI Architecture of FM0Manchester Encoding Using SOLS Technique for DSRC Applications
The dedicated short-range communication (DSRC) is an emerging technique to push the intelligent transportation system into our daily life. The DSRC standards generally adopt FM0 and Manchester codes to reach dc-balance, enhancing the signal reliability. Nevertheless, the coding-diversity between the FM0 and Manchester codes seriously limits the potential to design a fully reused VLSI architecture for both. In this paper, the similarity-oriented logic simplification (SOLS) technique is proposed to overcome this limitation. The encoding capability of this paper can fully support the DSRC standards of America, Europe, and Japan. This paper not only develops a fully reused VLSI architecture, but also exhibits an efficient performance compared with the existing works. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Glitch Energy Reduction and SFDR Enhancement Techniques for Low Power Binary Weighted Current Steering DAC
This brief proposes a glitch reduction approach by dynamic capacitance compensation of binary-weighted current switches in a current-steering digital-to-analog converter (DAC). The method was proved successfully by a 10-bit 400-MHz pure binary-weighted current steering DAC with a minimum number of retiming latches. The experiment results yield very low-glitch energy during major carry transitions at output.
List of the following materials will be included with the Downloaded Backup:
High Speed and Energy Efficient Carry Skip Adder Operating Under a Wide Range of Supply Voltage Levels
Abstract:
In this paper, we present a carry skip adder (CSKA) structure that has a higher speed yet lower energy consumption compared with the conventional one. The speed enhancement is achieved by applying concatenation and incrimination schemes to improve the efficiency of the conventional CSKA (Conv-CSKA) structure. In addition, instead of utilizing multiplexer logic, the proposed structure makes use of NAND-NOR-Invert (NNI) and NOR-NAND-Invert (NNI) compound gates for the skip logic. The structure may be realized with both fixed stage size and variable stage size styles, wherein the latter further improves the speed and energy parameters of the adder. Finally, a hybrid variable latency extension of the proposed structure, which lowers the power consumption without considerably impacting the speed, is presented. This extension utilizes a modified parallel structure for increasing the slack time, and hence, enabling further voltage reduction. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Implementation of Subthreshold Adiabatic Logic for Ultralow Power Application
Abstract:
The Subthreshold adiabatic logic for Ultralow power application is a novel approach is efficient in low speed operations, where power consumption and longevity are the pivotal concerns instead of performance. Here, we are implementing the adiabatic logic gates and implementing CLA 8-bit, it will compared to the normal logic gates, the adiabatic logic makes a more power consumption and also increasing speed. The schematic and layout of a 4-bit carry look ahead adder (CLA) has been implemented to show the workability of the proposed logic. The effect of temperature and process parameter variations on sub threshold adiabatic logic-based 4-bit CLA has also been addressed separately. Post layout simulations show that sub threshold adiabatic units can save significant energy compared with a logically equivalent static CMOS implementation.
List of the following materials will be included with the Downloaded Backup:
JF-Cut: A Parallel Graph Cut Approach for Large-Scale Image and Video
Graph cut has proven to be an effective scheme to solve a wide variety of segmentation problems in vision and graphics community. The main limitation of conventional graph-cut implementations is that they can hardly handle large images or videos because of high computational complexity. Even though there are some parallelization solutions, they commonly suffer from the problems of low parallelism (on CPU) or low convergence speed (on GPU). In this paper, we present a novel graph-cut algorithm that leverages a parallelized jump flooding technique and an heuristic push-relabel scheme to enhance the graph-cut process, namely, back-and-forth relabel, convergence detection, and block-wise push-relabel. The entire process is parallelizable on GPU, and outperforms the existing GPU-based implementations in terms of global convergence, information propagation, and performance. We design an intuitive user interface for specifying interested regions in cases of occlusions when handling video sequences. Experiments on a variety of data sets, including images (up to 15 K×10 K), videos (up to 2.5K×1.5K×50), and volumetric data, achieve highquality results and a maximum 40-fold (139-fold) speedup over conventional GPU (CPU-)-based approaches.
List of the following materials will be included with the Downloaded Backup:
Level-Converting Retention Flip-Flop for Reducing Standby Power in ZigBee SoCs
Abstract: In this paper, we are proposed a level converting retention flip-flop for Zigbee Soc, it will be using to allows the voltage regulator that generates the core supply voltage (VDD, core), to be turned off in the standby mode, and it thus reduces the standby power of the Zigbee Soc. Here the Level up conversion form VDD core is achieved by and embedded nMOS pass transistor level-conversion scheme that uses a low only signal transmitting technique. By embedding a retention latch and level-up converter into the data-to-output path of the proposed RFF, the RFF resolves the problems of the static RAM-based RFF, such as large dc current and low readability caused by threshold drop. The proposed RFF does not also require additional control signals for power mode transitioning. Using 0.13-μm process technology, we implemented an RFF with VDD,core and VDD,IO of 1.2 and 2.5 V, respectively. The maximum operating frequency is 300 MHz. The active energy of the RFF is 191.70 fJ, and its standby power is 350.25 pW.
List of the following materials will be included with the Downloaded Backup: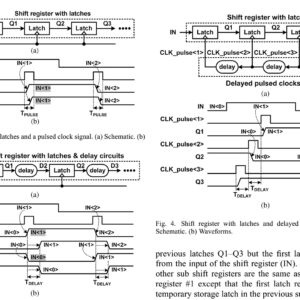
Low Power and Area Efficient Shift Register Using Pulsed Latches
Abstract: This paper proposes a low-power and area-efficient shift register using pulsed latches. The area and power consumption are reduced by replacing flip-flops with pulsed latches. This method solves the timing problem between pulsed latches through the use of multiple non-overlap delayed pulsed clock signals instead of the conventional single pulsed clock signal. The shift register uses a small number of the pulsed clock signals by grouping the latches to several sub shifter registers and using additional temporary storage latches. The proposed architecture of this paper analysis the area and power using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Low Power Compressor Based MAC Architecture for DSP Applications
This paper presents the low power compressor based Multiply-Accumulate (MAC) architecture for DSP applications. In VLSI, highly computed arithmetic cells including adders and multipliers are the most copiously used components. Efficient implementation of arithmetic logic units, floating point units and other dedicated functional components are utilized in most of the microprocessors and digital signal processors (DSPs). Thus in this brief, compressor circuit has been illustrated for the low power applications and also the impact of datapath circuits has been demonstrated. The proposed low power compressor architecture was applied to MAC unit and compared against the conventional compressor based MAC units and observed that the proposed architecture has reduced significant amount of leakage power. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
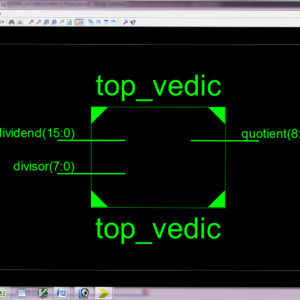
Low Power Divider Using Vedic Mathematics
Vedic mathematics is a unique technique of carrying out mathematical computations and it has its roots in the ancient Indian Mathematics. This paper presents the divider architecture using one of the Vedic mathematics techniques called as Paravartya-Yojayet, which means to transpose and apply. This paper proposes a fast, low power and cost effective architecture of a divider using the ancient Indian Vedic division algorithm. The merits of the proposed architecture are proved by comparing the gate count, power consumption and delay against the conventional divider architectures. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup: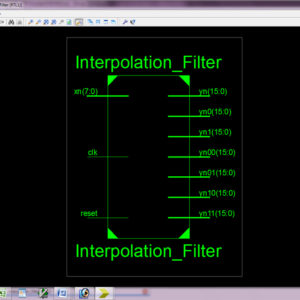
Novel Block-Formulation and Area-Delay-Efficient Reconfigurable Interpolation Filter Architecture for Multi-Standard SDR Applications
Abstract: The input-matrix and the coefficient-matrix resizes when changes. An analysis of interpolation filter computation for different up-sampling factors is made in this paper to identify redundant computations and removed those by reusing partial results. Reuse of partial results eliminates the necessity of matrix resizing in interpolation filter computation. A novel block-formulation is presented to share the partial results for parallel computation of filter outputs of different up-sampling factors. Using the proposed block formulation, to increase the number of tab to 16 and to get the accuracy and reduce the delay. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Obfuscating DSP Circuits via High Level Transformations
This paper presents a novel approach to design obfuscated circuits for digital signal processing (DSP) applications using high-level transformations, a key-based obfuscating finite-state machine (FSM), and a reconfigurator. The goal is to design DSP circuits that are harder to reverse engineer. High level transformations of iterative data-flow graphs have been exploited for area-speed-power tradeoffs. This is the first attempt to develop a design flow to apply high level transformations that not only meet these tradeoffs but also simultaneously obfuscate the architectures both structurally and functionally. Functional obfuscation is accomplished by requiring use of the correct initialization key, and configure data. Structural obfuscation is also achieved by the proposed methodology via high-level transformations. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2
List of the following materials will be included with the Downloaded Backup:
Pre Encoded Multipliers Based on Non Redundant Radix 4 Signed Digit Encoding
Abstract: In this paper we are discussed about the new design of pre-encoded multiplier are explored at offline the standard co efficient and storing them in system memory. The co efficient is used in non redundant radix 4 signed digit form. This encoding technique is less complex partial product implementation and more area and power efficient design. Analysis is verifies the proposed system is efficient from the existing system.
List of the following materials will be included with the Downloaded Backup:
Quaternary Logic Lookup Table in Standard CMOS
Abstract: Interconnections are increasingly the dominant contributor to delay, area and energy consumption in CMOS digital circuits. The proposed implementation overcomes several limitations found in previous quaternary implementations published so far, such as the need for special features in the CMOS process or power-hungry current-mode cells. We have to use the 512bit quaternary Look Up Table for high level of operations in the FPGA. The proposed architecture of this paper will be planned to implemented and also analysis the output current, output voltage, area using Xilinx 14.3.
List of the following materials will be included with the Downloaded Backup: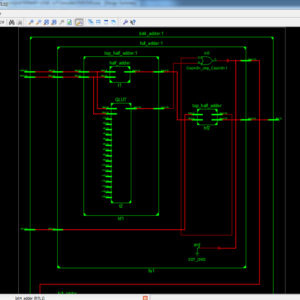
Quaternary Logic Lookup Table in Standard CMOS
Abstract: Interconnections are increasingly the dominant contributor to delay, area and energy consumption in CMOS digital circuits. The proposed implementation overcomes several limitations found in previous quaternary implementations published so far, such as the need for special features in the CMOS process or power-hungry current-mode cells. We have to use the 512bit quaternary Look Up Table for high level of operations in the FPGA.The proposed architecture of this paper will be planned to implemented and also analysis the output current, output voltage, area using Xilinx 14.3.
List of the following materials will be included with the Downloaded Backup: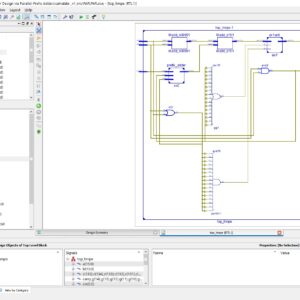
Reverse Converter Design via Parallel-Prefix Adders: Novel Components, Methodology, and Implementations
Abstract: The implementation of residue number system reverse converters based on well-known regular and modular parallel prefix adders is analyzed. The VLSI implementation results show a significant delay reduction and area × time2 improvements, all this at the cost of higher power consumption, which is the main reason preventing the use of parallel-prefix adders to achieve high-speed reverse converters in nowadays systems. Hence, to solve the high power consumption problem, novel specific hybrid parallel-prefix-based adder components those provide better tradeoff between delay and power consumption. The power, area and delay of the proposed system are analysis using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup: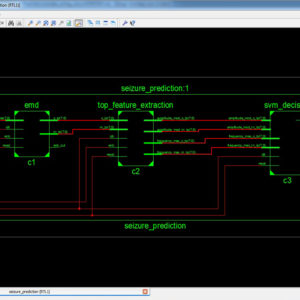
Seizure Prediction using Hilbert Huang Transform on Field Programmable Gate Array
The Hilbert Huang Transform (HHT) has been used extensively in the time-frequency analysis of electroencephalography (EEG) signals and Brain-Computer Interfaces. Most studies utilizing the HHT for extracting features in seizure prediction have used intracranial EEG recordings. Invasive implants in the cortex have unknown long term consequences and pose the risk of complications during surgery. This added risk dimension makes them unsuitable for continuous monitoring as would be the requirement in a Body Area Network. We present an HHT based system on Field Programmable Gate Array (FPGA) for predicting epileptic seizures using scalp EEG. We use bandwidth features of Intrinsic Mode Functions and obtain a classification accuracy of close to 100% using patient-specific classifiers in software. Details of FPGA implementation are also given. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:

To develop and Implement Low Power, High Speed VLSI for Processing Signals using Multi rate Techniques Low Power Divider Using Vedic Mathematics
Abstract:
Multirate technique is necessary for systems with different input and output sampling rates. Recent advances in mobile computing and communication applications demand low power and high speed VLSI DSP systems. In this paper to discuss the downsampling technique and its improvement, major drawbacks of present approaches possible to increase degeneracy. This Multirate design methodology is systematic and applicable to many problems. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup: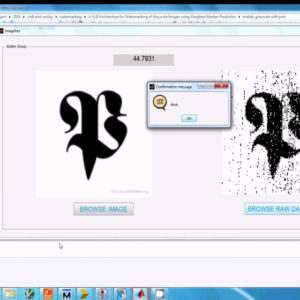
VLSI Implementation of Efficient Image Watermarking Algorithm
Abstract:
The watermarking is the important multimedia content for authentication and security in nowadays. We are proposed to implement the watermarking in FPGA with VLSI architecture. And also use the Haar discrete wallet transform and bit plane slicing for creating the water marking images and extracted watermark images. The area, power, delay of the proposed architecture is analysis using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
VLSI-Oriented Lossy Image Compression Approach using DA-Based 2D-Discrete Wavelet
We introduced a Discrete Wavelet Transform (DWT) based VLSI-oriented lossy image compression approach, widely used as the core of digital image compression. Here, Distributed Arithmetic (DA) technique is applied to determine the wavelet coefficients, so that the number of arithmetic operation can be reduced substantially. As well, the compression rate is enhanced with the aid of introducing RW block that blocks some of the coefficients obtained from the high pass filter to zero. Subsequently, Differential Pulse-Code Modulation (DPCM) and huffman-encoding are applied to acquire the binary sequence of the image. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:IEEE Transactions on VLSI, VLSI IEEE Project, VLSI Low Power Project, VLSI High Speed Project, VLSI Area Efficient Project, Low Cost VLSI Projects, High Speed VLSI Design projects ( CDMA, RTOS, DSP, RF, IF, etc), Low Power VLSI Design projects, Area Efficient VLSI Design projects , Audio processing VLSI Design projects, Signal Processing VLSI Design projects, Image Processing VLSI Design projects, Backend VLSI Design projects ( CMOS, TFET, BisFET, FeFET, etc), Timing & Delay Reduction VLSI Projects, Internet of Things VLSI Projects, Testing, Reliability and Fault Tolerance VLSI Projects, VLSI Applications ( Communicational, Video, Security, Sensor Networks, etc), SOC VLSI Projects, Network on Chip VLSI Projects, Wireless Communication VLSI Projects, VLSI Verifications Projects ( UVM, OVM, VVM, System Verilog.
Provide Wordlwide Online Support
We can provide Online Support Wordlwide, with proper execution, explanation and additionally provide explanation video file for execution and explanations.
24/7 Support Center
NXFEE, will Provide on 24x7 Online Support, You can call or text at +91 9789443203, or email us nxfee.innovation@gmail.com
Terms & Conditions:
Customer are advice to watch the project video file output, and before the payment to test the requirement, correction will be applicable.
After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
Online support will not be given more than 3 times.
On first time explanation we can provide completely with video file support, other 2 we can provide doubt clarifications only.
If any Issue on Software license / System Error we can support and rectify that within end of day.
Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
After payment, to must send the payment receipt to our email id.
Powered by NXFEE INNOVATION, Pondicherry.
Call us today at : +91 9789443203 or Email us at nxfee.innovation@gmail.com
NXFEE Development & Services

Product Categories
- 2014 (11)
- 2015 (39)
- 2016 (30)
- 2017 (16)
- 2018 (17)
- 2019 (42)
- 2020 (29)
- 2021 (17)
- 2022 (23)
- Accessories (43)
- Area Efficient (116)
- High speed VLSI Design (56)
- IEEE (15)
- Image Processing (40)
- Low power VLSI Design (97)
- NOC VLSI Design (2)
- VLSI (249)
- VLSI 2023 (21)
- VLSI 2024 (18)
- VLSI 2025 (30)
- VLSI 2026 (3)
- VLSI Application / Interface and Mini Projects (31)
- VLSI_2023 (15)
Filter by price
Product Status
Sort by rating
Sort by producents

Copyright © 2026 Nxfee Innovation.