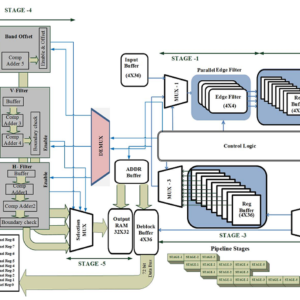
Design and Implementation of Efficient Streaming Deblocking and SAO Filter for HEVC Decoder
We have also Code for 720 x 576 Image Resolution using 64 x 64 Block Size of HEVC. Cost of this Update work in High Resolution Rs. 45,000/- ( Rs. 45,000/- + Rs. 30,000/- ) : Total Cost : Rs. 75,000/-
Abstract:
This paper aims to design an efficient mixed serial five-stage pipeline processing hardware architecture of deblocking filter (DBF) and sample adaptive offset (SAO) filter for high efficiency video coding decoder. The proposed hardware is designed to increase the throughput and reduce the number of clock cycles by processing the pixels in a stream of 4 × 36 samples in which edge filters are applied vertically in a parallel fashion for processing of luma/chroma samples. Subsequently these filtered pixels are transposed and reprocessed through vertical filter for horizontal filtering in a pipeline fashion. Finally, the filtered block transposed back to the original orientation and forwarded to a three-stage pipeline SAO filter. The proposed architecture is implemented in field programmable gate array and application specific integrated circuit platform using 90-nm library. Experimental results illustrate that the proposed DBF and SAO architecture decreases the processing cycles (172) required for processing each 64 × 64 or large coding unit compared with the state-of-the-art literature with the increase of gate count (593.32K) including memory. The results show that the throughput of the proposed filter can successfully decode ultrahigh definition video sequences at 200 frames/s at 341 MHz.
List of the following materials will be included with the Downloaded Backup:
Design and Low-Complexity Implementation of Matrix–Vector Multiplier for Iterative Methods in Communication Systems
Abstract: Iterative methods are basic building blocks of communication systems and often represent a dominating part of the system, and therefore, they necessitate careful design and implementation for optimal performance. In this brief, we propose a novel field programmable gate arrays design of matrix–vector multiplier that can be used to efficiently implement widely adopted iterative methods. The proposed design exploits the sparse structure of the matrix as well as the fact that spreading code matrices have equal magnitude entries. Implementation details and timing analysis results are promising and are shown to satisfy most modern communication system requirements.
List of the following materials will be included with the Downloaded Backup:
Design Methodology for Voltage Scaled Clock Distribution Networks
Abstract:
A low-voltage/swing clocking methodology is developed through both circuit and algorithmic innovations. The primary objective is to significantly reduce the power consumed by the clock network while maintaining the circuit performance the same. a novel D-flip-flop (DFF) cell that maximizes power savings by enabling low-voltage/swing operation throughout the entire clock network . In this proposed design of the LSFF is consume the less power compare to existing design. The proposed architecture of this paper is analysis the logic size, area and power consumption using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Design of 4-bit Ripple carry adder and using 9T full adder
Design of a Scalable Low Power 1 bit Hybrid Full Adder for Fast Computation
Abstract:
A novel design of a hybrid Full Adder (FA) using Pass Transistors (PTs), Transmission Gates (TGs) and Conventional Complementary Metal Oxide Semiconductor (CCMOS) logic is presented. Performance analysis of the circuit has been conducted using Cadence toolset. For comparative analysis, the performance parameters have been compared with twenty existing FA circuits. The proposed FA has also been extended up to a word length of 64 bits in order to test its scalability. Only the proposed FA and five of the existing designs have the ability to operate without utilizing buffer in intermediate stages while extended to 64 bits. According to simulation results, the proposed design demonstrates notable performance in power consumption and delay which accounted for low power delay product. Based on the simulation results, it can be stated that the proposed hybrid FA circuit is an attractive alternative in the data path design of modern high-speed Central Processing Units.
List of the following materials will be included with the Downloaded Backup:
Design of Approximate Restoring Divider
Proposed Abstract:
Approximate computing is an emerging paradigm in error-tolerant applications that leads to power-efficient designs without significant loss in quality. The divider in these applications have complex hardware and more latency among the computational blocks resulting in power consumption. Hence approximating the division module would lead to designs with vastly improved power efficiency. A new approximate subtractor (AxSUB) is proposed in this paper with the intent to reduce the hardware complexity while achieving accuracy within permissible limits. The proposed AxSUB and existing approximate subtractor units are used in the restoring array division (RAD) architecture to prove the efficacy of the AxSUB. This proposed architecture design with 8/4 approximate divider using Verilog HDL and synthesized using Xilinx Spartan 6 FPGA, and proved the performance of area, delay and power.
List of the following materials will be included with the Downloaded Backup:
Design of Area-Efficient and Highly Reliable RHBD 10T Memory Cell for Aerospace Applications
Abstract:
In this brief, based on upset physical mechanism together with reasonable transistor size, a robust 10T memory cell is first proposed to enhance the reliability level in aerospace radiation environment, while keeping the main advantages of small area, low power, and high stability. Using Taiwan Semiconductor Manufacturing Company 65-nmCMOS commercial standard process, simulations performed in Cadence Spectre demonstrate the ability of the proposed radiation-hardened-by-design 10T cell to tolerate both 0 →1and1→0 single node upsets, with the increased read/write access time.
List of the following materials will be included with the Downloaded Backup:
Design of High Speed 8-bit Vedic Multiplier using Brent Kung Parallel Prefix Adder
Base Paper Abstract:
One of the primary purposes of a digital signal processing system is multiplication. The multiplier’s performance affects the DSP system’s overall performance. Therefore, it is crucial to create an effective and quick multiplier implementation design. Vedic mathematics can be used to simplify complex computations so that they are easier to perform verbally. Urdhva Triyambakam is the multiplication algorithm used in Vedic math. In this paper, we employing Brent Kung adder to enhance the Vedic multiplier’s performance. The Urdhva Tiryagbhyam sutra is being used in place of other multiplication strategies since it applies to all instances of algorithms for N x N bit numbers and produces the least amount of latency. Four 4-bit vedic multipliers, two 8-bit Brent Kung adders, one 4-bit Brent Kung adder, and an OR gate are used to create an 8-bit vedic multiplier. A 4-bit vedic multiplier is created similarly by combining four 2-bit vedic multipliers, two 4-bit Brent Kung Adders, one 2-bit Brent Kung Adder, and one OR gate. These four-bit vedic multipliers are then combined to form an eight-bit vedic multiplier. After that, Xilinx Vivado Software is used to simulate and synthesis the 8 x 8 Vedic Multiplier, which was coded in Verilog HDL. The proposed Vedic Multiplier is outperformed in terms of speed when compared to related works.
List of the following materials will be included with the Downloaded Backup: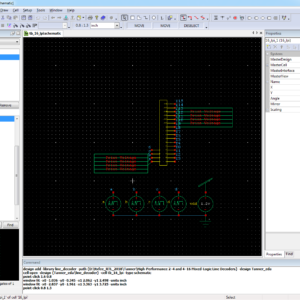
Design of Low Power High Performance 2-4 and 4-16 Mixed-Logic Line Decoders
Abstract:
This paper introduces a mixed-logic design method for line decoders, combining transmission gate logic, pass transistor dual-value logic and static CMOS. Two novel topologies are presented for the 2-4 decoders: a 14-transistor topology aiming on minimizing transistor count and power dissipation and a 15-transistor topology aiming on high power delay performance. Both a normal and an inverting decoder are implemented in each case, yielding a total of four new designs. Furthermore, four new 4-16 decoders are designed, by using mixed-logic 2-4 pre decoders combined with standard CMOS post-decoder. All proposed decoders have full swinging capability and reduced transistor count compared to their conventional CMOS counterparts. Finally, a variety of comparative spice simulations at the 32 nm shows that the proposed circuits present a significant improvement in power and delay, outperforming CMOS in almost all cases.
List of the following materials will be included with the Downloaded Backup:
Design of Power and Area Efficient Approximate Multipliers
Abstract:
Approximate computing can decrease the design complexity with an increase in performance and power efficiency for error resilient applications. This brief deals with a new design approach for approximation of multipliers. The partial products of the multiplier are altered to introduce varying probability terms. Logic complexity of approximation is varied for the accumulation of altered partial products based on their probability. The proposed approximation is utilized in two variants of 16-bit multipliers. Synthesis results reveal that two proposed multipliers achieve power savings of 72% and 38%, respectively, compared to an exact multiplier. They have better precision when compared to existing approximate multipliers. Mean relative error figures are as low as 7.6% and 0.02% for the proposed approximate multipliers, which are better than the previous works. Performance of the proposed multipliers is evaluated with an image processing application, where one of the proposed models achieves the highest peak signal to noise ratio.
List of the following materials will be included with the Downloaded Backup: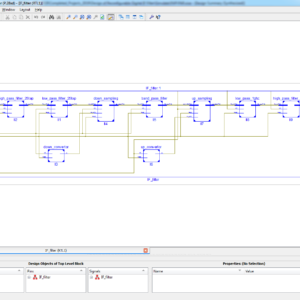
Design of Reconfigurable Digital IF Filter with Low Complexity
Abstract:
Due to limited frequency resources, new services are being applied to the existing frequencies, and service providers are allocating some of the existing frequencies for newly enhanced mobile communications. Because of this frequency environment, repeater and base station systems for mobile communications are becoming more complicated, and frequency interference caused by multiple bands and services is getting worse. Therefore, a heterodyne receiver using IF filters with high selectivity has been used to minimize the interference between frequencies. However, repeater and base station systems in mobile communications employing fixed IF filters cannot actively cope with the usage of multiple frequency bands, the application of various services, and frequency recycling. Therefore, this brief proposes a reconfigurable digital IF filter with variable center frequency and bandwidth while achieving high selectivity as existing IF filters. The center frequency of filter can vary from 10MHz to 62.5MHz, and the filter bandwidth can be selective to one of 10MHz, 15MHz, and 20MHz. The proposed digital filter also reduces the complexity of adders and multipliers by 38.81% and 41.57%, respectively, compared to an existing digital filter by using a filter bank and a multi stage structure. This digital IF filter is fabricated on a 130-nm CMOS process and occupies 5.90 mm2.
List of the following materials will be included with the Downloaded Backup: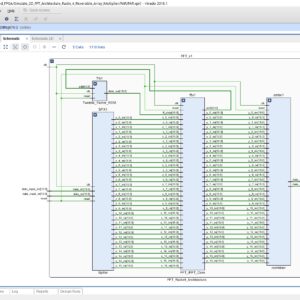
Design of SEU Tolerant 2D-FFT in SRAM-based FPGA
Base Paper Abstract:
2-Dimensional fast Fourier transform (FFT) has been widely used in radar signal process. Due to the need for high performance, field programmable gate array (FPGA) is an ideal hardware device for this application. For space-borne radar platform such as synthetic aperture radar (SAR), single-event upsets (SEUs) can cause lots of soft errors in static random access memory (SRAM) based FPGA. As to this, protecting the 2D-FFT implemented in FPGA from SEUs is very important. In this article, we analyze the critical weakness induced by SEUs in the 2D-FFT process, and then a 2D-FFT design with high SEU resilience is presented. The design utilizes the advantage of several anti-SEU methods. For butterfly control in FFT, partially triple modular redundancy (TMR) is used. For data buffers, error correction code (ECC) is applied to read and write operation. Furthermore, safe finite state machine (FSM) is adopted by important control registers. Fault injection results show that all these reinforcement technologies contribute to enhance the ability to mitigate the SEU effects.
List of the following materials will be included with the Downloaded Backup:
Design of Sparse FIR Filters With Reduced Effective Length
Abstract:
In this paper, an exchange algorithm is proposed to design sparse linear phase finite impulse response (FIR) filters with reduced effective length. The sparse FIR filter design problem is formally an l0-norm minimization problem. This original design problem is re-formulated by encoding the filter coefficients using a binary encoding vector, which represents the locations of the zero and non-zero filter coefficients. An iterative 0-1 exchange process with proper direction control is proposed to propel the minimax approximation error toward the specified upper bound of error for sparsity maximization. The effective length is optimized with a lower priority than sparsity in the proposed algorithm. Simulation results show that the proposed algorithm is superior to the existing algorithms in terms of both sparsity and/or effective length in most cases.
List of the following materials will be included with the Downloaded Backup:
Design of Testable Reversible Sequential Circuits
Abstract: In this paper, we propose the design of two vectors testable sequential circuits based on conservative logic gates. The proposed sequential circuits based on conservative logic gates outperform the sequential circuits implemented in classical gates in terms of testability. Any sequential circuit based on conservative logic gates can be tested for classical unidirectional stuck-at faults using only two test vectors. The two test vectors are all 1s, and all 0s. The designs of two vectors testable latches, master-slave flip-flops and double edge triggered (DET) flip-flops are presented. The importance of the proposed work lies in the fact that it provides the design of reversible sequential circuits completely testable for any stuck-at fault by only two test vectors, thereby eliminating the need for any type of scan-path access to internal memory cells. The reversible design of the DET flip-flop is proposed for the first time in the literature. We also showed the application of the proposed approach toward 100% fault coverage for single missing/additional cell defect in the quantum dot cellular automata (QCA) layout of the Fredkin gate. We are also presenting a new conservative logic gate called multiplexer conservative QCA gate (MX-cqca) that is not reversible in nature but has similar properties as the Fredkin gate of working as 2:1 multiplexer. The proposed MX-cqca gate surpasses the Fredkin gate in terms of complexity (the number of majority voters), speed, and area.
List of the following materials will be included with the Downloaded Backup:
Design of ultra-low power consumption approximate 4-2 compressors based on the compensation characteristic
Abstract:
Approximate computing is tentatively applied in some digital signal processing applications which have an inherent tolerance for erroneous computing results. The approximate arithmetic blocks are utilized in them to improve the electrical performance of these circuits. Multiplier is one of the fundamental units in computer arithmetic blocks. Moreover, the 4-2 compressors are widely employed in the parallel multipliers to accelerate the compression process of partial products. In this paper, three novel approximate 4-2 compressors are proposed and utilized in 8-bit multipliers. Meanwhile, an error-correcting module (ECM) is presented to promote the error performance of approximate multiplier with the proposed 4-2 compressors. In this paper, the number of the approximate 4-2 compressor’s outputs is innovatively reduced to one, which brings further improvements in the energy efficiency. Compared with the exact 4-2 compressors, the simulation results indicate that the proposed approximate compressors UCAC1, UCAC2, UCAC3 achieve 24.76%, 51.43%, and 66.67% reduction in delay, 71.76%, 83.06%, and 93.28% reduction in power and 54.02%, 79.32%, and 93.10% reduction in area, respectively. And the utilization of these proposed compressors in 8-bit multipliers brings 49.29% reduction of power consumption on average.
List of the following materials will be included with the Downloaded Backup:
Determining Application-Specific Knowledge for Improving Robustness of Sequential Circuits
Base Paper Abstract:
Due to their shrinking feature sizes as well as environmental influences, such as high-energy radiation, electrical noise, and particle strikes, integrated circuits are getting more vulnerable to transient faults. Accordingly, how to make those circuits more robust has become an essential step in today’s design flows. Methods increasing the robustness of circuits against these faults already exist for a long period of time but either introduce huge additional logic, change the timing behavior of the circuit, or are applicable for dedicated circuits such as microprocessors only. In this paper, we propose an alternative method, which overcomes these drawbacks by determining application specific knowledge of the circuit, namely the relations of flip-flops and when they assume the same value. By this, we exploit partial redundancies, which are inherent in most circuits anyway (even the optimized ones), to frequently compare the circuit signals for their correctness—eventually leading to an increased robustness. Since determining the correspondingly needed information is a computationally hard task, formal methods, such as bounded model checking, satisfiability-based automatic test pattern generation, and binary decision diagrams, are utilized for this purpose. The resulting methodology requires only a slight increase in additional hardware, does only influence the timing behavior of the circuit negligibly, and is automatically applicable to arbitrary circuits. Experimental evaluations confirm these benefits.
List of the following materials will be included with the Downloaded Backup:
Dual Quality 4:2 Compressor for Utilizing in Dynamic Accuracy Configurable Multipliers
Abstract:
In this paper, we propose four 4:2 compressors, which have the flexibility of switching between the exact and approximate operating modes. In the approximate mode, these dual-quality compressors provide higher speeds and lower power consumptions at the cost of lower accuracy. Each of these compressors has its own level of accuracy in the approximate mode as well as different delays and power dissipations in the approximate and exact modes. Using these compressors in the structures of parallel multipliers provides configurable multipliers whose accuracies (as well as their powers and speeds) may change dynamically during the runtime. The proposed multiplier saves few adder circuits in partial products, and this proposed multiplier is evaluated with an image processing application. In existing thing, to using this multiplier to design image processing evaluation on only luminance based application, but here the proposed work is modified with Gaussian noise reduction with luminance and chrominance based application, this design to implemented in VHDL, and synthesized in Xilinx S6LX9 FPGA and shown the power, area and delay reports.
List of the following materials will be included with the Downloaded Backup:
Dual Use of Power Lines for Design for Testability A CMOS Receiver Design
As the circuit complexity increases, the number of internal nodes increases proportionally, and individual internal nodes are less accessible due to the limited number of available I/O pins. To address the problem, we proposed power line communications (PLCs) at the IC level, specifically the dual use of power pins and power distribution networks for application/ observation of test data as well as delivery of power. A PLC receiver presented in this paper intends to demonstrate the proof of concept, specifically the transmission of data through power lines. The main design objective of the proposed PLC receiver is the robust operation under variations and droops of the supply voltage rather than high data speed. The PLC receiver is designed and fabricated in CMOS 0.18-µm technology under a supply voltage of 1.8V.
List of the following materials will be included with the Downloaded Backup:
Efficient Design for Fixed-Width Adder-Tree
Abstract:
Conventionally, fixed-width adder-tree (AT) design is obtained from the full-width AT design by employing direct or post-truncation. In direct-truncation, one lower order bit of each adder output of full-width AT is post-truncated, and in case of post-truncation, {p} lower order-bits of final-stage adder output are truncated, where p = dlog2 Ne and N is the input-vector size. Both these methods do not provide an efficient design. In this paper, a novel scheme is presented to obtain fixed-width AT design using truncated input. A bias estimation formula based on probabilistic approach is presented to compensate the truncation error. The proposed fixed-width AT design for input-vector sizes 8 and 16 offers (37%, 23%, 22%) and (51%, 30%, 27%) area delay product (ADP) saving for word-length sizes (8, 12, 16), respectively, and calculates the output almost with the same accuracy as the post-truncated fixed-width AT which has the highest accuracy among the existing fixed-width AT. Further, we observed that Walsh-Hadamard transform based on the proposed fixed-width AT design reconstruct higher-texture images with higher peak signal to noise ratio (PSNR) and moderate-texture images with almost the same PSNR compared to those obtained using the existing AT designs. Besides, the proposed design creates an additional advantage to optimize other blocks appear at the upstream of the AT in a complex design.
List of the following materials will be included with the Downloaded Backup:
Efficient Design of Behavioral Clock Divider for Multiple Frequency
Proposed Abstract:
Frequency dividers are of utmost importance in frequency synthesizers that are based on phase locked loops. The use of dual modulus presales enhances the versatility of the design in both integer and Fractional-N frequency synthesizers. The selection of an acceptable division ratio is dependent upon the channel spacing and frequency range of the synthesizer. There are several techniques for division in electronic systems, including the injection locked frequency divider (ILFD), complementary ILFDs, flip flop based dividers, dual modulus dividers, and modular dividers. Therefore, these approaches possess some advantages and disadvantages, such as reduced jitter, a restricted frequency tuning range, increased circuit size due to the addition of an LC tank circuit, increased power consumption, and lower quality factor. This work aims at addressing certain issues pertaining to clock dividers and proposes a unique design that utilizes a multiple digital frequency divider based on D flip flops. The architectural design is predicated on the use of a phase shifting mechanism using a D flip flop, which effectively controls the division ratio. The present study involves the use of a preliminary phase shifting melody in conjunction with the Digital Clock Manager (DCM). The auto tuning strategy described in this study aims to adjust the phase difference between two differential clock signals. By intentionally inducing metastability in one or more flip flops, the proposed approach utilizes a digital clock manager in a clock divider to mitigate the effects of metastability and reduce jitter across multiple tuning frequencies. Furthermore, it is worth noting that the logic size and power consumption required for its operation are significantly reduced.
List of the following materials will be included with the Downloaded Backup: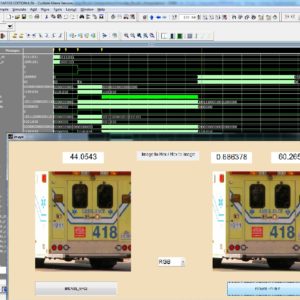
Efficient Super Resolution Algorithm using Overlapping Bi-cubic Interpolation
Abstract:
In practical CCTV applications, there are problems of the camera with low resolution, camera fields of view, and lighting environments. These could degrade the image quality and it is difficult to extract useful information for further processing. Super-resolution techniques have been proposed widely by the researchers. However, many approaches are complex and are difficult to use in practical scenarios. In this paper, we propose an efficient Super-resolution algorithm using overlapping bi-cubic for hardware implementation. Experimental results are verified using processing time and reconstructed images that can be used in real time applications.
List of the following materials will be included with the Downloaded Backup:
Efficient TCAM Design Based on Multipumping Enabled Multiported SRAM on FPGA
Abstract:
Ternary content-addressable memory (TCAM)-based search engines play an important role in networking routers. The search space demands of TCAM applications are constantly rising. However, existing realizations of TCAM on field-programmable gate arrays (FPGAs) suffer from storage inefficiency. This paper presents a multipumping-enabled multiported SRAM-based TCAM design on FPGA, to achieve an efficient utilization of SRAM memory. Existing SRAM-based solutions for TCAM reduce the impact of the increase in the traditional TCAM pattern width from an exponential growth in memory usage to a linear one using cascaded block RAMs (BRAMs) on FPGA. However, BRAMs on state-of-the-art FPGAs have a minimum depth limitation, which limits the storage efficiency for TCAM bits. Our proposed solution avoids this limitation by mapping the traditional TCAM table divisions to shallow sub-blocks of the configured BRAMs, thus achieving a memory-efficient TCAM memory design. The proposed solution operates the configured simple dual-port BRAMs of the design as multiported SRAM using the multipumping technique, by clocking them with a higher internal clock frequency to access the sub-blocks of the BRAM in one system cycle. We implemented our proposed design on a Virtex-6 xc6vlx760 FPGA device. Compared with existing FPGA-based TCAM designs, our proposed method achieves up to 2.85 times better performance per memory.
List of the following materials will be included with the Downloaded Backup:
Energy-Efficient Approximate Multiplier Design using Bit Significance-Driven Logic Compression
Abstract:
Approximate arithmetic has recently emerged as a promising paradigm for many imprecision-tolerant applications. It can offer substantial reductions in circuit complexity, delay and energy consumption by relaxing accuracy requirements. In this paper, we propose a novel energy-efficient approximate multiplier design using a significance-driven logic compression (SDLC) approach. Fundamental to this approach is an algorithmic and configurable lossy compression of the partial product rows based on their progressive bit significance. This is followed by the commutative remapping of the resulting product terms to reduce the number of product rows. As such, the complexity of the multiplier in terms of logic cell counts and lengths of critical paths is drastically reduced. A number of multipliers with different bit-widths (4-bit to 128-bit) are designed in System Verilog and synthesized using Synopsys Design Compiler. Post-synthesis experiments showed that up to an order of magnitude energy savings, and reductions of 65% in critical delay and almost 45% in silicon area can be achieved for a 128-bit multiplier compared to an accurate equivalent. These gains are achieved with low accuracy losses estimated at less than 0.00071 mean relative error. Additionally, we demonstrate the energy-accuracy trade-offs for different degrees of compression, achieved through configurable logic clustering. In evaluating the effectiveness of our approach, a case study image processing application showed up to 68.3% energy reduction with negligible losses in image quality expressed as peak signal-to-noise ratio (PSNR).
List of the following materials will be included with the Downloaded Backup:
Energy-Efficient VLSI Realization of Binary64 Division With Redundant Number Systems
Base Paper Abstract:
VLSI realizations of digit-recurrence binary division usually use redundant representation of partial remainders and quotient digits. The former allows for fast carry-free computation of the next partial remainder, and the latter leads to less number of the required divisor multiples. In studying the previous relevant works, we have noted that the binary carry save (CS) number system is prevalent in the representation of partial remainders, and redundant high radix representation of quotient digits is popular in order to reduce the cycle count. In this paper, we explore a design space containing four division architectures. These are based on binary CS or radix-16 signed digit (SD) representations of partial remainders. On the other hand, they use full or partial pre computation of divisor multiples. The latter uses smaller multiplexer at the cost two extra adders, where one of the operands is constant within all cycles. The quotient digits are represented by radix-16 [−9,9]SDs. Our synthesis-based evaluation of VLSI realizations of the best previous relevant work and the four proposed designs show reduced power and energy figures in the proposed designs at the cost of more silicon area and delay measures. However, our energy-delay product is 26%–35% less than that of the reference work.
List of the following materials will be included with the Downloaded Backup:
Energy-Quality Scalable Adders Based on Non-zeroing Bit Truncation
Abstract:
Approximate addition is a technique to trade off energy consumption and output quality in error-tolerant applications. In prior art, bit truncation has been explored as a lever to dynamically trade off energy and quality. In this brief, an innovative bit truncation strategy is proposed to achieve more graceful quality degradation compared to state-of-the-art truncation schemes. This translates into energy reduction at a given quality target. When applied to a ripple-carry adder, the proposed bit truncation approach improves quality by up to 8.5 dB in terms of peak signal-to-noise ratio, compared to traditional bit truncation. As a case study, the proposed approach was applied to a discrete cosine transform engine. In comparison with prior art, the proposed approach reduces energy by 20%, at insignificant delay and silicon area overhead.
List of the following materials will be included with the Downloaded Backup:
ER-TCAM: A Soft-Error-Resilient SRAM-Based Ternary Content-Addressable Memory for FPGAs
Abstract:
Static random access memory (SRAM)-based ternary content-addressable memory (TCAM) on field-programmable gate arrays (FPGAs) is used for packet classification in software-defined networking (SDN) and Open Flow applications. SRAMs implementing TCAM contents constitute the major part of a TCAM design on FPGAs, which are vulnerable to soft errors. The protection of SRAM-based TCAMs against soft errors is challenging without compromising critical path delay and maintaining a high search performance. This brief presents a low cost and low-response-time technique for the protection of SRAM-based TCAMs. This technique uses simple, single-bit parity for fault detection which has a minimal critical path overhead. This technique exploits the binary-encoded TCAM table maintained in SRAM-based TCAMs for update purposes to implement a low-response-time error-correction mechanism at low cost. The error-correction process is carried out in the background, allowing lookup operations to be performed simultaneously, thus maintaining a high search performance. The proposed technique provides protection against soft errors with a response time of 293 ns, whereas maintaining a search rate of 222 million searches per second on a 1024 × 40 size TCAM on Artix-7 FPGA.
List of the following materials will be included with the Downloaded Backup:
Error Detection and Correction in SRAM Emulated TCAMs
Abstract:
Ternary content addressable memories (TCAMs) are widely used in network devices to implement packet classification. They are used, for example, for packet forwarding, for security, and to implement software-defined networks (SDNs). TCAMs are commonly implemented as standalone devices or as an intellectual property block that is integrated on networking application-specific integrated circuits. On the other hand, field-programmable gate arrays (FPGAs) do not include TCAM blocks. However, the flexibility of FPGAs makes them attractive for SDN implementations, and most FPGA vendors provide development kits for SDN. Those need to support TCAM functionality and, therefore, there is a need to emulate TCAMs using the logic blocks available in the FPGA. In recent years, a number of schemes to emulate TCAMs on FPGAs have been proposed. Some of them take advantage of the large number of memory blocks available inside modern FPGAs to use them to implement TCAMs. A problem when using memories is that they can be affected by soft errors that corrupt the stored bits. The memories can be protected with a parity check to detect errors or with an error correction code to correct them, but this requires additional memory bits per word. In this brief, the protection of the memories used to emulate TCAMs is considered. In particular, it is shown that by exploiting the fact that only a subset of the possible memory contents are valid, most single-bit errors can be corrected when the memories are protected with a parity bit.
List of the following materials will be included with the Downloaded Backup:
Fast and Hardware-Efficient Variable Step Size Adaptive Beamformer
Base Paper Abstract:
Constant step size least mean square (CSS-LMS) is one of the most popular adaptive beamforming algorithms. However, for varying channel signal-to-noise ratios (SNRs), the CSS algorithms are not effective, and there is a need for variable step size (VSS) algorithms. The VSS algorithms provide extremely deep nulls for the interferences; however, they are complex to implement on hardware. Hence, this paper proposes two hardware-efficient variable step size algorithms, namely, efficient variable step size LMS (EVSS-LMS) and reduced complexity parallel LMS (EVSS-RC-pLMS). The proposed EVSS algorithms eliminate the complex operations of VSS algorithms like division and exponential and approximate them to simpler operations. Further, MATLAB simulations demonstrate accelerated convergence, deep nulls, a lower error floor, and better performance in varying SNR environments for the proposed algorithms. Additionally, the finite precision radiation patterns are similar to infinite precision. Hardware synthesis results show the outstanding performance of EVSS in terms of resource utilization on the Xilinx Artix-7 FPGA.
List of the following materials will be included with the Downloaded Backup:
Feed forward-Cutset-Free Pipelined Multiply–Accumulate Unit for the Machine Learning Accelerator
Abstract:
Multiply–accumulate (MAC) computations account for a large part of machine learning accelerator operations. The pipelined structure is usually adopted to improve the performance by reducing the length of critical paths. An increase in the number of flip-flops due to pipelining, however, generally results in significant area and power increase. A large number of flip-flops are often required to meet the feed forward-cutset rule. Based on the observation that this rule can be relaxed in machine learning applications, we propose a pipelining method that eliminates some of the flip-flops selectively. The simulation results show that the proposed MAC unit achieved a 20% energy saving and a 20% area reduction compared with the conventional pipelined MAC.
List of the following materials will be included with the Downloaded Backup:
FIR Filter Design based on FPGA
Abstract:
FIR (Finite Impulse Response) Filters: the finite impulse response filter is the most basic components in digital signal processing systems are widely used in communications, image processing, and pattern recognition. Based on FPGA(editable logic device) to achieve FIR filter, not only take into account the fixed -function DSP-specific chip real-time, but also has the DSP processor flexibility. The combination of FPGA and DSP technology can further improve integration, increase work speed and expand system capabilities.
List of the following materials will be included with the Downloaded Backup:
Floating Point Butterfly Architecture Based on Binary Signed Digit Representation
Fast Fourier transform (FFT) coprocessor, having a significant impact on the performance of communication systems, has been a hot topic of research for many years. The FFT function consists of consecutive multiply add operations over complex numbers, dubbed as butterfly units. Applying floating-point (FP) arithmetic to FFT architectures, specifically butterfly units, has become more popular recently. It offloads compute-intensive tasks from general-purpose processors by dismissing FP concerns (e.g., scaling and overflow/underflow). However, the major downside of FP butterfly is its slowness in comparison with its fixed-point counterpart. This reveals the incentive to develop a high-speed FP butterfly architecture to mitigate FP slowness. This brief proposes a fast FP butterfly unit using a devised FP fused-dot product-add (FDPA) unit, to compute AB±CD±E, based on binary signed-digit (BSD) representation. The FP three-operand BSD adder and the FP BSD constant multiplier are the constituents of the proposed FDPA unit. A carry-limited BSD adder is proposed and used in the three-operand adder and the parallel BSD multiplier so as to improve the speed of the FDPA unit. Moreover, modified Booth encoding is used to accelerate the BSD multiplier. The synthesis results show that the proposed FP butterfly architecture is much faster than previous counterparts but at the cost of more area. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup: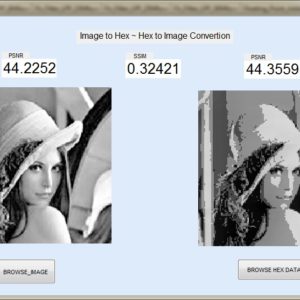
Floating-point discrete wavelet transform-based image compression on FPGA
Abstract:
In the era of data transmission through internet, image compression is considered an active research topic, decreasing the amount of data storage for faster data transfer. In this paper, the hardware implementation of an image compression system using Discrete Wavelet Transform (DWT) is presented. The transposed form Finite Impulse Response (FIR) filter is employed for performing the convolution process, on which the DWT is based. The design is generic to fit for different wavelet types and symmetric to expand for filters of multiple taps. The architecture is implemented on FPGA using IEEE-754 single precision. Floating-Point representation offered higher precision and better accuracy compared to scaled integer values. The proposed hardware design is implemented on Virtex 5 FPGA achieving 243.6 MHz clock frequency.
List of the following materials will be included with the Downloaded Backup:
FPGA Based High Definition SPWM Generation With Harmonic Mitigation Property
Abstract:
High-resolution sinusoidal pulse width modulation (SPWM) switching is beneficial in order to achieve compact size and fine sinusoidal output of dc–ac converters. In this article, a novel field-programmable gate array (FPGA) based high-definition SPWM (HD-SPWM) architecture is proposed for adopting a scheme of integrating a lower frequency PWM train to a high-frequency SPWM train in order to suppress inverter output harmonics while achieving high resolution output. An optimized FPGA based two-stage finite-state-machine (FSM) architecture is designed, where the initial stage decides pulse widths of a lower frequency PWM train based on the premeditated pulse width of the high-frequency SPWM train, whereas in the final stage, lower frequency PWM pulse widths are integrated with the high-frequency SPWM pulse widths to generate updated pulse widths of high-frequency SPWM, i.e., HD-SPWM. Moreover, a pre-formulation mathematical model is established for the calculation of duty-cycle count values of pulse trains to support the online adjustment of modulation index (MI) of the HD-SPWM. The proposed generation has the benefits of harmonic mitigation, online fine adjustment of MI, low-processing time, and requirement of a minor segment of a medium-sized FPGA; thereby, providing a good tradeoff between larger designs and higher performance. Theoretical calculations, characteristics, and design contemplations are specified, and the HD-SPWM generation is demonstrated through experimentation with a Xilinx Spartan-3 FPGA board.
List of the following materials will be included with the Downloaded Backup:
FPGA Based True Random Number Generation Using Programmable Delays in Oscillator Rings
Abstract:
True random number generators play a fundamental role in cryptographic systems. This paper presents a new and efficient method to generate true random numbers on field programmable gate array by utilizing the random jitter of free running oscillators as a source of randomness. The free-running oscillator rings incorporate programmable delay lines to generate large variation of the oscillations and to introduce jitter in the generated ring oscillators clocks. The main advantage of the proposed true random number generator utilizing programmable delay lines is to reduce correlation between several equal length oscillator rings, and thus improve the randomness qualities. In addition, a Von Neumann corrector as post-processor is employed to remove any bias in the output bit sequence. The validation of the proposed approach is demonstrated on Xilinx Spartan-3A FPGAs. The proposed true random number generator occupies 528 slices, achieves 6 Mbps throughput with 0.999 per bit entropy rate, and passes all the National Institute of Standards and Technology (NIST) statistical tests.
List of the following materials will be included with the Downloaded Backup:
FPGA Heart Rate Monitoring (Pre Processing – QRS Detection Stage)
Base Paper Abstract:
The continuous monitoring of cardiac patients requires an ambulatory system that can automatically detect heart diseases. This study presents a new field programmable gate array (FPGA)-based hardware implementation of the QRS complex detection. The proposed detection system is mainly based on the Pan and Tompkins algorithm, but applying a new, simple, and efficient technique in the detection stage. The new method is based on the centered derivative and the intermediate value theorem, to locate the QRS peaks. The proposed architecture has been implemented on FPGA using the Xilinx System Generator for digital signal processor and the Nexys-4 FPGA evaluation kit. To evaluate the effectiveness of the proposed system, a comparative study has been performed between the resulting performances and those obtained with existing QRS detection systems, in terms of reliability, execution time, and FPGA resources estimation. The proposed architecture has been validated using the 48 half-hours of records obtained from the Massachusetts Institute of Technology - Beth Israel Hospital (MITBIH) arrhythmia database. It has also been validated in real time via the analogue discovery device.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of 64 Block Data Encryption Standard Algorithm
Proposed Abstract:
The Data Encryption Standard (DES) is widely recognized as the inaugural and prevailing symmetric key method used for the cryptographic processes of encrypting and decrypting digital data. Despite its lack of security against determined attackers in contemporary times, the use of this method persists in older systems. This work introduces a novel implementation of the Data Encryption and Decryption Standard algorithm using Field Programming Gate Arrays (FPGAs) that prioritizes security, high throughput, and space efficiency. The suggested solution involves the creation of a system that utilizes a block size of 64 bits and a key length that is also 64 bits. Additionally, the system operates with a data width of 64 bits. This achievement is accomplished by integrating the notion of pipelining with time variable permutations, and then comparing it with previously shown encryption techniques. The permutations undergo temporal variations under the control of the cryptographer. Hence, the cipher text also undergoes alteration while the key and plaintext remain constant. The algorithm under consideration has been successfully executed on the Xilinx Vetex-5 Field-Programmable Gate Array (FPGA) platform. The findings of this study indicate that the suggested implementation exhibits exceptional speed in comparison to other hardware implementations. Additionally, it demonstrates superior area efficiency and significantly enhanced security measures.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of 8×8 Truncated Multiplier
Proposed Abstract:
The operation of multiplication is an often encountered need in the field of digital signal processing. Parallel multipliers provide a rapid approach for performing multiplication operations, while demanding a significant amount of space in VLSI (Very Large Scale Integration) implementations. In the majority of signal processing applications, there is a preference for using a rounded result in order to prevent an increase in the size of the word. Therefore, an important goal in the design process is to minimize the spatial demand of the rounded output multiplier. This study introduces a novel approach to parallel multiplication that efficiently calculates the products of two n-bit values by selectively summing the most important columns using a variable correction technique. This research furthermore includes a comparative analysis of the implementation of 8X8 conventional and truncated multipliers using Verilog Hardware Description Language (HDL) on Field Programmable Gate Arrays (FPGAs). The shortened multiplier demonstrates a much greater decrease in device consumption as compared to the regular multiplier. A conventional multiplier performs computations on n x n bits and produces a weighted sum of the output, consisting of 2n bits. In contrast, a truncated multiplier generates an output of just n bits from the n x n bit input. The use of logic gates in both internal and external hardware design will be decreased. Truncated multipliers provide a viable approach for achieving significant reductions in FPGA resources, latency, and power consumption compared to regular parallel multipliers, particularly in scenarios where the complete accuracy provided by the standard multiplier is unnecessary.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of D8PSK Demodulator
Base Paper Abstract:
Differential phase shift keying (DPSK) is a modulation scheme that facilitates non coherent demodulation and is employed for various applications such as Wireless Local Area Networks (WLANs), Bluetooth and RFID communication. In this paper, design, development and hardware implementation of a new demapping scheme for Differential 8-PSK (D8PSK) demodulator on a Zynq 7000 FPGA based ZED board is proposed using the concepts of model based design. The proposed work can be easily extended to other M-ary DPSK schemes.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of Epileptic Seizure Detection Using ELM Classifier Detection Using ELM Classifier
Abstract:
Electroencephalography (EEG) Signals are widely used to determine the brain disorders. The Electrical activity of human brain is recorded in the form of EEG signal. The abnormal Electrical activity of the human brain is called as epileptic seizure. In epilepsy patients, the seizure occurs at unpredictable times and it causes sudden death. Detection and Prediction of Epileptic seizure is performed by analyzing the EEG signal. The EEG signal of human brain is random in nature, hence detection of seizure in EEG signal is challenging task. Hardware implementation of Epileptic seizure detection system is necessary for real time applications. In this work an accurate approach is used to identify the Epileptic seizure and that is implemented in FPGA (Field Programmable Gate Array).The hardware implementation of epileptic seizure detection algorithm is done using Xilinx System generator tool. In the first step the EEG signal is extracted from the human brain and it is filtered by using Finite Impulse response (FIR) band pass filter. The band pass filter separates the EEG signal into delta, theta, alpha, beta and gamma brain rhythms. The band separated brain signal is modeled by linear prediction theory. In the next step features are extracted from the modeled EEG signal and the classification of normal or seizure signal is done by using Extreme Learning Machine (ELM) classifier. The EEG signals used in this paper were obtained from Epilepsy Center at the University of Bonn, Germany. The hardware architecture, Look up tables, resource utilization, Accuracy and power consumption of the algorithm is analyzed using xilinx zynq7000 all programmable soc.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of High Performance Reversible logic based 16×16 Array Multiplier
Proposed Abstract:
In this recent technology of digital gadgets and digital signal processing and image processing method will have more priority in arithmetic operation, such as multiplication, divisions, addition and subtractions. In this operations of arithmetic unit will have number of garbage signal with more memory logic element, due to this problem these arithmetic operations will take more area, delay and power in VLSI system design. Here, this proposed work will present a arithmetic operation using reversible logic method, thus it take memory less logic and less garbage elements, therefore here this reversible logic method will integrated using reversible half adders and full adder in array multiplier and proved the performance with less garbage signals. Finally, this work will have integrated in Verilog HDL, simulated in Modelsim and Synthesized in Xilinx FPGA, and also compared all the parameter in terms of area, delay and power.
List of the following materials will be included with the Downloaded Backup: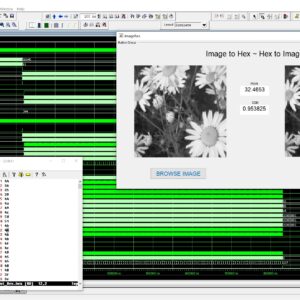
FPGA Implementation of Image Line Buffer to Split and reconstruct a 3×3 size of image pixel with using FIFO Design
Proposed Abstract:
Image line buffers are used in several kinds of image processing applications, particularly where operations must be executed on a per-line basis in order to optimize efficiency. There are many typical applications associated with this technology, including real-time video processing, image filtering, edge detection, computer vision, memory optimization, parallel processing, compression algorithms, and medical imaging. In the context of image and video processing applications, the use of image line buffers may contribute to the optimization of operations when dealing with a continuous stream of frames processed in real time. In the context of image processing, convolutional processes are often used for tasks like as image filtering and blurring. These operations are typically carried out on a per-pixel basis, wherein the value assigned to each pixel is determined by the values of its adjacent pixels. The proposed structure was created using a First-In-First-Out (FIFO) based approach, aiming to decrease the number of logic sizes and complexity in Very Large Scale Integration (VLSI) design architecture. The conversion of design images to hexadecimal and hexadecimal to image format is accomplished using MATLAB GUI applications. These applications also facilitate the comparison of Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) values. The internal architecture of the system is implemented using Verilog Hardware Description Language (HDL). Additionally, the simulation is conducted using Modelsim. Furthermore, the system's performance parameters, including area, delay, and power consumption, are compared with those of the Xilinx Vertex-5 Field Programmable Gate Array (FPGA).
List of the following materials will be included with the Downloaded Backup: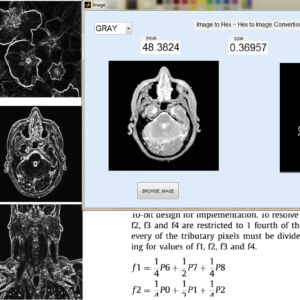
FPGA implementation of low power and high speed image edge detection algorithm
Abstract:
Image processing is a vital task in data processing system for applications in medical fields, remote sensing, microscopic imaging etc., Algorithms for processing image exist except for real time system style, hardware implementation is most popular principally. This paper presents a design for Sobel filter based edge detection on Field Programmable Gate Array (FPGA) board. Hardware implementation of the Sobel edge detection algorithm is chosen because it presents an honest scope for similarity over software package. On the opposite hand, Sobel edge detection will work with less deterioration in high level of noise. Edges are primarily the noticeable variation of intensities in a picture. Edges facilitate to spot the placement of an object and also the boundary of a selected entity within the image. It conjointly helps in feature extraction and pattern recognition. Hence, edge detection is of nice importance in pc vision. The planned design for edge detection exploitation Sobel algorithm is designed using structural Verilog lipoprotein synthesized exploitation Cadence Genus and enforced using Cadence Innovus. The practicality of the planning is verified exploitation normal pictures by FPGA implementation. The proposed architecture reduce the power, delay and space complexity compare to three existing architectures.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of Partially Parallel Encoder Architecture for Long Polar Code
Polar coding is an encoding/decoding scheme that provably achieves the capacity of the class of symmetric binary memory-less channels. Due to the channel achieving property, the polar code has become one of the most favourable error-correcting codes. As the polar code achieves the property asymptotically, however, it should be long enough to have a good error-correcting performance. Although previous fully parallel encoder is intuitive and easy to implement, it is not suitable for long polar codes because of the huge hardware complexity required. In the brief, we analyse the encoding process in the viewpoint of very large-scale integration implementation and propose a new efficient encoder architecture that is adequate for long polar codes and effect in alleviating the hardware complexity. As the proposed encoder allows high-throughput encoding with small hardware complexity, it can be systematically applied to the design of any polar code and to any level of parallelism. Finally shown the power, area, delay report with comparison of existing work.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of Single Precision Floating Point Multiplier using High Speed Parallel Prefix Adder based Wallace Tree Multiplier
Base Paper Abstract:
In this paper present, an efficient implementation of single precision method of floating point multiplier target for Xilinx Vertex 5 FPGA using Verilog HDL. The floating point implementation will cover up with 23-bit exponent, 8-bit mantissa, and 1 sign bit. This proposed architecture implement with high speed parallel prefix adder based Wallace Tree Multiplier. a Wallace tree multiplication will provide effective terms of low logic sizes and more speed of operations. In a recent arithmetic applications based circuit design will have more demand with high speed and low area, in this manner the proposed approach of this work will improve the speed of Wallace tree multiplier using 4:2 compressor method without degrading its area parameter. Thus, the proposed method will integrate more efficient and more reliable Kogge stone parallel prefix, Brent kung parallel prefix, Sklansky parallel prefix addition operation in the Wallace tree multiplication on final addition stage at 16-bit data width. Finally, done this floating point multiplier architecture with Wallace tree architecture included normalized rounding method and to reduce area, delay and power. The error difference will have analyzed using Modelsim Software, and analyses optimized logic size's, delay and power consumptions.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of Spread Spectrum Clock Generator with Onion Modulation
Proposed Abstract:
A Spread Spectrum Clock Generator (SSCG) is used in electronics to purposefully vary the frequency of a clock signal via modulation. Modulation is accomplished by dispersing the energy of the signal throughout a spectrum of frequencies rather than focusing it on a certain frequency. The main objective of using the spread spectrum approach in clock generation is to minimize electromagnetic interference (EMI) and enhance electromagnetic compatibility (EMC) in electronic systems. The main reason for using many layers of modulation in spread spectrum clock production, regardless of whether the name "Onion Modulation" is used, is to provide a more advanced and adaptable method for reducing electromagnetic interference. The primary design feature of the onion wave is that the core portion of the waveform has the least steep slope, which serves to generate the output. In order to optimize the frequency effect design, the conventional approach involves using a memory ROM to regulate the slope and obtain the desired onion waveform. This current methodology necessitates substantial memory allocation and an intricate architecture, resulting in higher power consumption. The proposed method presents a unique architecture for onion modulation, which offers reduced logic size and power usage. This architecture was created using Verilog HDL, tested using Modelsim, and implemented using the Xilinx Vertex-5 FPGA.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of TFT 1.8 inch SPI 128×160 Display ROM Interface
Simple Description:
This ST7735R is a display controller used in small TFT (Thin-Film Transistor) LCD displays. It is often used in combination with microcontrollers or FPGAs to drive these displays. The controller supports the Serial Peripheral Interface mode of communication for sending commands and data to the display. This TFT display helps with a greater number of image and video processing applications. Here we have implemented this TFT display in FPGA hardware implementation using Verilog HDL with a novelty-based architecture design. Finally shown the output with TFT Display.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of the Adaptive Digital Beamforming for Massive Array
Base Paper Abstract:
With the rise of 5G networks and the increasing number of communication devices, improving communication quality is essential. One approach is adaptive digital beamforming, which adjusts an antenna array’s radiation pattern based on the desired received signal. Adaptation based on Least-Mean Squared (LMS) and its variants is still one of the most common literature methods. Although LMS techniques present good computational performance, the increase in antennas’ numbers led to high-performance hardware. Platforms such as Field Programmable Gate Arrays (FPGAs), designed for massive array systems, enables high-performance energy-efficient architectures. This work proposes a parallel implementation of a massive array beamforming composed of a spatial filter and adaptation unit based on LMS on FPGA. The proposed design presents ten times fewer hardware requirements and 30 times less power consumption than state of the art.
List of the following materials will be included with the Downloaded Backup:
FPGA-Based System For Heart Rate Monitoring
Abstract:
The continuous monitoring of cardiac patients requires an ambulatory system that can automatically detect heart diseases. This study presents a new field programmable gate array (FPGA)-based hardware implementation of the QRS complex detection. The proposed detection system is mainly based on the Pan and Tompkins algorithm, but applying a new, simple, and efficient technique in the detection stage. The new method is based on the centred derivative and the intermediate value theorem, to locate the QRS peaks. The proposed architecture has been implemented on FPGA using the Xilinx System Generator for digital signal processor and the Nexys-4 FPGA evaluation kit. To evaluate the effectiveness of the proposed system, a comparative study has been performed between the resulting performances and those obtained with existing QRS detection systems, in terms of reliability, execution time, and FPGA resources estimation. The proposed architecture has been validated using the 48 half-hours of records obtained from the Massachusetts Institute of Technology - Beth Israel Hospital (MITBIH) arrhythmia database. It has also been validated in real time via the analogue discovery device.
List of the following materials will be included with the Downloaded Backup:
Frequency-Boost Jitter Reduction for Voltage-Controlled Ring Oscillators
Ring oscillators (ROs) are popular due to their small area, modest power, wide tuning range, and ease of scaling with process technology. However, their use in many applications is limited due to poor phase noise and jitter performance. Thermal noise and flicker noise contribute jitter that decreases inversely with oscillation frequency. This paper describes a frequency boost technique to reduce jitter in ROs. We boost the internal oscillation frequency and introduce a frequency divider following the oscillator to maintain the desired output frequency. This approach offers reduced jitter as well as the opportunity to trade off output jitter with power for dynamic performance management. The oscillator has 32 operating modes, corresponding to different values for the ring size and frequency division. In a 0.5-µm CMOS process, the highest oscillation frequency achieved is 25 MHz with a root-mean-square period jitter of 54 ps and a power consumption of 817 µW at 5 V supply. A jitter model for current-starved oscillators was derived and verified by measurement; a direct relationship between oscillation frequency and jitter was derived and measured. Compared with other oscillators, this design achieves the highest performance in terms of jitter per unit interval and figure-of-merit. The performance is expected to improve in more advanced technologies. The results are summarized to offer design guidance based on the frequency boost technique. The proposed architecture of this paper area and power consumption analysis using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Full Swing Local Bitline SRAM Architecture Based on the 22 nm FinFET Technology for Low Voltage Operation
The previously proposed average-8T static random access memory (SRAM) has a competitive area and does not require a write-back scheme. In the case of an average-8T SRAM architecture, a full-swing local bitline (BL) that is connected to the gate of the read buffer can be achieved with a boosted wordline (WL) voltage. However, in the case of an average-8T SRAM based on an advanced technology, such as a 22-nm FinFET technology, where the variation in threshold voltage is large, the boosted WL voltage cannot be used, because it degrades the read stability of the SRAM. Thus, a full-swing local BL cannot be achieved, and the gate of the read buffer cannot be driven by the full supply voltage (VDD), resulting in a considerably large read delay. To overcome the above disadvantage, in this paper, a differential SRAM architecture with a full-swing local BL is proposed. In the proposed SRAM architecture, full swing of the local BL is ensured by the use of cross-coupled pMOSs, and the gate of the read buffer is driven by a full VDD, without the need for the boosted WL voltage. Various configurations of the proposed SRAM architecture, which stores multiple bits, are analyzed in terms of the minimum operating voltage and area per bit. The proposed SRAM that stores four bits in one block can achieve a minimum voltage of 0.42 V and a read delay that is 62.6 times lesser than that of the average-8T SRAM based on the 22-nm FinFET technology. The proposed architecture of this paper is analysis the area and power consumption using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Provide Wordlwide Online Support
We can provide Online Support Wordlwide, with proper execution, explanation and additionally provide explanation video file for execution and explanations.
24/7 Support Center
NXFEE, will Provide on 24x7 Online Support, You can call or text at +91 9789443203, or email us nxfee.innovation@gmail.com
Terms & Conditions:
Customer are advice to watch the project video file output, and before the payment to test the requirement, correction will be applicable.
After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
Online support will not be given more than 3 times.
On first time explanation we can provide completely with video file support, other 2 we can provide doubt clarifications only.
If any Issue on Software license / System Error we can support and rectify that within end of day.
Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
After payment, to must send the payment receipt to our email id.
Powered by NXFEE INNOVATION, Pondicherry.
Call us today at : +91 9789443203 or Email us at nxfee.innovation@gmail.com
NXFEE Development & Services

Copyright © 2021 Nxfee Innovation.